Structured Streaming プログラミングガイド
- 目次
非同期プログレス追跡
概要
非同期プログレス追跡により、ストリーミングクエリはマイクロバッチ内の実際のデータ処理と並行して、非同期にプログレスをチェックポイント化できます。これにより、オフセットログやコミットログの管理に関連するレイテンシが削減されます。
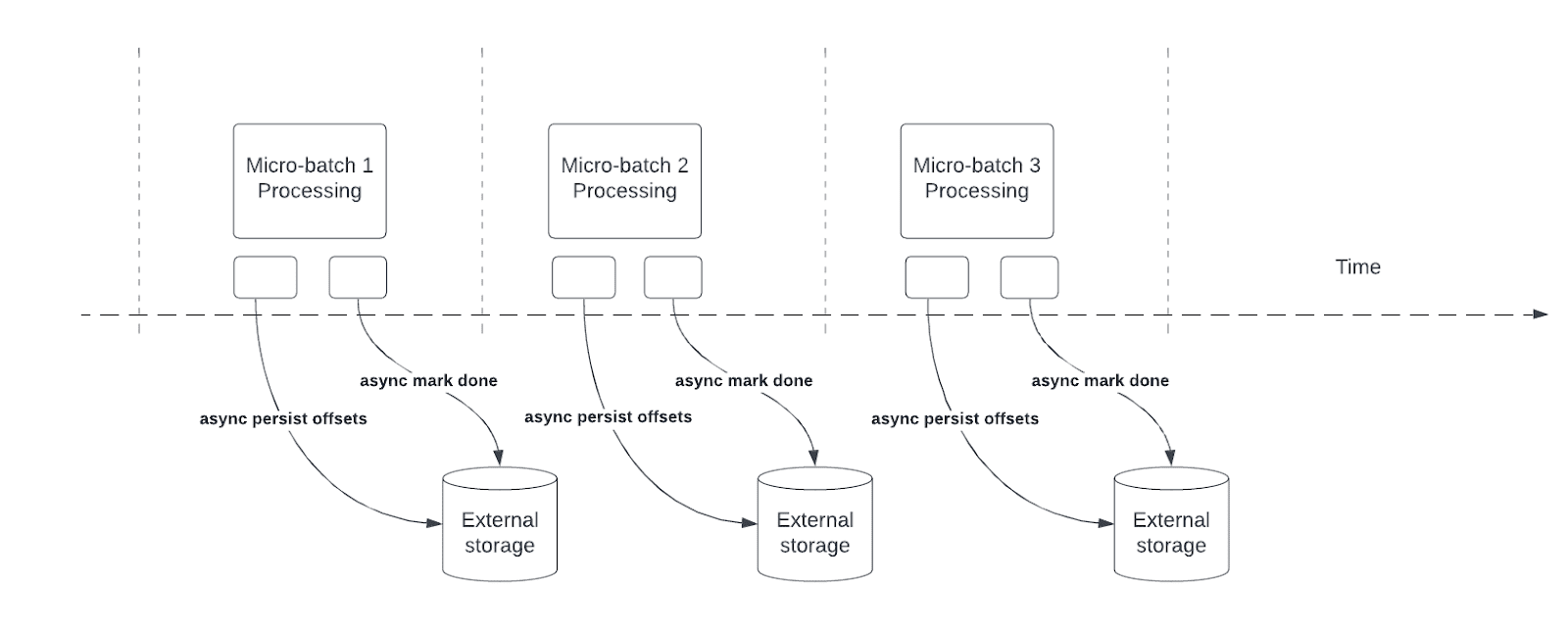
仕組み
Structured Streaming は、クエリ処理のプログレスインジケーターとしてオフセットを永続化および管理することに依存しています。オフセット管理操作は処理レイテンシに直接影響します。なぜなら、これらの操作が完了するまでデータ処理は行われないからです。非同期プログレス追跡により、ストリーミングクエリはこれらのオフセット管理操作の影響を受けずにプログレスをチェックポイント化できます。
使用方法
以下のコードスニペットは、この機能の使用方法の例を示しています。
val stream = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "in")
.load()
val query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.start()
以下の表は、この機能の設定とそれに関連するデフォルト値について説明しています。
| オプション | 値 | デフォルト | 説明 |
|---|---|---|---|
| asyncProgressTrackingEnabled | true/false | false | 非同期プログレス追跡の有効化または無効化 |
| asyncProgressTrackingCheckpointIntervalMs | ミリ秒 | 1000 | オフセットと完了コミットをコミットする間隔 |
制限事項
この機能の初期バージョンには、以下の制限があります。
- 非同期プログレス追跡は、Kafka Sink を使用するステートレスクエリでのみサポートされています。
- この非同期プログレス追跡では、障害発生時にバッチのオフセット範囲が変更される可能性があるため、エンドツーエンドでの正確に1回の処理はサポートされません。ただし、Kafka Sink のように多くの Sink は、そもそも正確に1回の処理をサポートしていません。
設定の無効化
非同期プログレス追跡を無効にすると、以下の例外が発生する可能性があります。
java.lang.IllegalStateException: batch x doesn't exist
また、ドライバーログに以下のエラーメッセージが出力される場合があります。
The offset log for batch x doesn't exist, which is required to restart the query from the latest batch x from the offset log. Please ensure there are two subsequent offset logs available for the latest batch via manually deleting the offset file(s). Please also ensure the latest batch for commit log is equal or one batch earlier than the latest batch for offset log.
これは、非同期プログレス追跡が有効になっている場合、フレームワークは非同期プログレス追跡が使用されていない場合に行われるような、各バッチのプログレスをチェックポイント化しないという事実によって引き起こされます。この問題を解決するには、単に "asyncProgressTrackingEnabled" を再度有効にし、"asyncProgressTrackingCheckpointIntervalMs" を 0 に設定して、少なくとも2つのマイクロバッチが処理されるまでストリーミングクエリを実行してください。これで非同期プログレス追跡を安全に無効にでき、クエリの再起動は正常に進むはずです。
継続処理
[実験的]
継続処理 は、Spark 2.3 で導入された新しい実験的なストリーミング実行モードであり、少なくとも1回のフォールトトレランス保証で低(約1 ms)のエンドツーエンドレイテンシを可能にします。これと比較すると、デフォルトのマイクロバッチ処理エンジンは、正確に1回の保証を達成できますが、最良でも約100 ms のレイテンシしか達成できません。一部のクエリタイプ(以下で説明)では、アプリケーションロジックを変更せずに(つまり、DataFrame/Dataset 操作を変更せずに)どちらのモードで実行するかを選択できます。
サポートされているクエリを継続処理モードで実行するには、パラメータとして目的のチェックポイント間隔を持つ **継続トリガー** を指定するだけで十分です。たとえば、
spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.option("subscribe", "topic1") \
.load() \
.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)") \
.writeStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.option("topic", "topic1") \
.trigger(continuous="1 second") \ # only change in query
.start()import org.apache.spark.sql.streaming.Trigger
spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1")
.load()
.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "topic1")
.trigger(Trigger.Continuous("1 second")) // only change in query
.start()import org.apache.spark.sql.streaming.Trigger;
spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1")
.load()
.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "topic1")
.trigger(Trigger.Continuous("1 second")) // only change in query
.start();1 秒のチェックポイント間隔は、継続処理エンジンが 1 秒ごとにクエリのプログレスを記録することを意味します。結果として得られるチェックポイントは、マイクロバッチエンジンと互換性のある形式であるため、どのクエリでも再起動できます。たとえば、マイクロバッチモードで開始されたサポートされているクエリは、継続モードで再起動できます。逆も同様です。継続モードに切り替えるたびに、少なくとも1回のフォールトトレランス保証が得られることに注意してください。
サポートされるクエリ
Spark 2.4 時点では、継続処理モードでは以下の種類のクエリのみがサポートされています。
- 操作: 継続モードでは、map のような Dataset/DataFrame 操作のみがサポートされています。つまり、射影(
select、map、flatMap、mapPartitionsなど)と選択(where、filterなど)のみです。- 集計関数(集計はまだサポートされていないため)、
current_timestamp()、current_date()(時間を使用した決定論的な計算は困難)を除く、すべての SQL 関数がサポートされています。
- 集計関数(集計はまだサポートされていないため)、
- ソース:
- Kafka ソース: すべてのオプションがサポートされています。
- Rate ソース: テストに適しています。継続モードでサポートされているオプションは、
numPartitionsとrowsPerSecondのみです。
- Sink:
- Kafka Sink: すべてのオプションがサポートされています。
- Memory Sink: デバッグに適しています。
- Console Sink: デバッグに適しています。すべてのオプションがサポートされています。コンソールは、継続トリガーで指定した各チェックポイント間隔を出力することに注意してください。
詳細については、入力ソース および 出力 Sink のセクションを参照してください。コンソール Sink はテストに適していますが、エンドツーエンドの低レイテンシ処理は、ソースと Sink として Kafka を使用すると最もよく観察できます。これにより、エンジンはデータ処理を行い、入力トピックで利用可能な入力データから数ミリ秒以内に結果を出力トピックで利用可能にすることができます。
注意点
- 継続処理エンジンは、データソースから継続的にデータを読み取り、処理し、Sink に継続的に書き込む複数の長時間実行タスクを起動します。クエリに必要なタスクの数は、クエリがソースから並列で読み取ることができるパーティションの数によって異なります。したがって、継続処理クエリを開始する前に、クラスターにすべてのタスクを並列で処理するための十分なコアがあることを確認する必要があります。たとえば、10 個のパーティションを持つ Kafka トピックから読み取る場合、クエリが進むにはクラスターに少なくとも 10 個のコアが必要です。
- 継続処理ストリームを停止すると、偽のタスク終了警告が表示される場合があります。これらは安全に無視できます。
- 現在、失敗したタスクの自動再試行はありません。いずれかの障害が発生すると、クエリは停止し、チェックポイントから手動で再起動する必要があります。