Structured Streaming プログラミングガイド
簡単な例
TCPソケットでリッスンしているデータサーバーから受信したテキストデータの実行中の単語数を維持したいとします。Structured Streamingを使用してこれをどのように表現できるか見てみましょう。完全なコードは、Python / Scala / Java / R で確認できます。また、Spark をダウンロードすると、例を直接実行することもできます。いずれにしても、例をステップバイステップで見て、その仕組みを理解しましょう。まず、必要なクラスをインポートし、ローカルのSparkSessionを作成する必要があります。これはSparkに関連するすべての機能の開始点です。
from pyspark.sql import SparkSession
from pyspark.sql.functions import explode
from pyspark.sql.functions import split
spark = SparkSession \
.builder \
.appName("StructuredNetworkWordCount") \
.getOrCreate()import org.apache.spark.sql.functions._
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder
.appName("StructuredNetworkWordCount")
.getOrCreate()
import spark.implicits._import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.sql.*;
import org.apache.spark.sql.streaming.StreamingQuery;
import java.util.Arrays;
import java.util.Iterator;
SparkSession spark = SparkSession
.builder()
.appName("JavaStructuredNetworkWordCount")
.getOrCreate();sparkR.session(appName = "StructuredNetworkWordCount")次に、localhost:9999 でリッスンしているサーバーから受信したテキストデータを表すストリーミングDataFrameを作成し、DataFrame を変換して単語数を計算します。
# Create DataFrame representing the stream of input lines from connection to localhost:9999
lines = spark \
.readStream \
.format("socket") \
.option("host", "localhost") \
.option("port", 9999) \
.load()
# Split the lines into words
words = lines.select(
explode(
split(lines.value, " ")
).alias("word")
)
# Generate running word count
wordCounts = words.groupBy("word").count()この lines DataFrame は、ストリーミングテキストデータを含むアンバウンドテーブルを表します。このテーブルには "value" という名前の文字列の1つの列があり、ストリーミングテキストデータの各行がテーブルの1行になります。これは、変換をセットアップしているだけで、まだ開始していないため、現在データを受信していないことに注意してください。次に、2つの組み込みSQL関数 - split と explode を使用して、各行を単語ごとの複数の行に分割しました。さらに、alias 関数を使用して新しい列を "word" と名付けました。最後に、Dataset の一意の値でグループ化してカウントすることにより、wordCounts DataFrame を定義しました。これは、ストリームの実行中の単語数を表すストリーミングDataFrameであることに注意してください。
// Create DataFrame representing the stream of input lines from connection to localhost:9999
val lines = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()
// Split the lines into words
val words = lines.as[String].flatMap(_.split(" "))
// Generate running word count
val wordCounts = words.groupBy("value").count()この lines DataFrame は、ストリーミングテキストデータを含むアンバウンドテーブルを表します。このテーブルには "value" という名前の文字列の1つの列があり、ストリーミングテキストデータの各行がテーブルの1行になります。これは、変換をセットアップしているだけで、まだ開始していないため、現在データを受信していないことに注意してください。次に、.as[String] を使用して DataFrame を String の Dataset に変換し、flatMap 操作を適用して各行を複数の単語に分割できるようにしました。結果の words Dataset にはすべての単語が含まれています。最後に、Dataset の一意の値でグループ化してカウントすることにより、wordCounts DataFrame を定義しました。これは、ストリームの実行中の単語数を表すストリーミングDataFrameであることに注意してください。
// Create DataFrame representing the stream of input lines from connection to localhost:9999
Dataset<Row> lines = spark
.readStream()
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load();
// Split the lines into words
Dataset<String> words = lines
.as(Encoders.STRING())
.flatMap((FlatMapFunction<String, String>) x -> Arrays.asList(x.split(" ")).iterator(), Encoders.STRING());
// Generate running word count
Dataset<Row> wordCounts = words.groupBy("value").count();この lines DataFrame は、ストリーミングテキストデータを含むアンバウンドテーブルを表します。このテーブルには "value" という名前の文字列の1つの列があり、ストリーミングテキストデータの各行がテーブルの1行になります。これは、変換をセットアップしているだけで、まだ開始していないため、現在データを受信していないことに注意してください。次に、.as(Encoders.STRING()) を使用して DataFrame を String の Dataset に変換し、flatMap 操作を適用して各行を複数の単語に分割できるようにしました。結果の words Dataset にはすべての単語が含まれています。最後に、Dataset の一意の値でグループ化してカウントすることにより、wordCounts DataFrame を定義しました。これは、ストリームの実行中の単語数を表すストリーミングDataFrameであることに注意してください。
# Create DataFrame representing the stream of input lines from connection to localhost:9999
lines <- read.stream("socket", host = "localhost", port = 9999)
# Split the lines into words
words <- selectExpr(lines, "explode(split(value, ' ')) as word")
# Generate running word count
wordCounts <- count(group_by(words, "word"))この lines SparkDataFrame は、ストリーミングテキストデータを含むアンバウンドテーブルを表します。このテーブルには "value" という名前の文字列の1つの列があり、ストリーミングテキストデータの各行がテーブルの1行になります。これは、変換をセットアップしているだけで、まだ開始していないため、現在データを受信していないことに注意してください。次に、2つのSQL関数 - split と explode を含むSQL式があり、各行を単語ごとの複数の行に分割します。さらに、新しい列を "word" と名付けます。最後に、wordCounts SparkDataFrame を SparkDataFrame の一意の値でグループ化してカウントすることにより定義しました。これは、ストリームの実行中の単語数を表すストリーミングSparkDataFrameであることに注意してください。
これで、ストリーミングデータに対するクエリがセットアップされました。あとは、実際にデータの受信とカウントの計算を開始するだけです。これを行うには、outputMode("complete") で指定されたカウントの完全なセットを、更新されるたびにコンソールに出力するように設定します。そして、start() を使用してストリーミング計算を開始します。
# Start running the query that prints the running counts to the console
query = wordCounts \
.writeStream \
.outputMode("complete") \
.format("console") \
.start()
query.awaitTermination()// Start running the query that prints the running counts to the console
val query = wordCounts.writeStream
.outputMode("complete")
.format("console")
.start()
query.awaitTermination()// Start running the query that prints the running counts to the console
StreamingQuery query = wordCounts.writeStream()
.outputMode("complete")
.format("console")
.start();
query.awaitTermination();# Start running the query that prints the running counts to the console
query <- write.stream(wordCounts, "console", outputMode = "complete")
awaitTermination(query)このコードが実行された後、ストリーミング計算はバックグラウンドで開始されます。query オブジェクトは、アクティブなストリーミングクエリへのハンドルであり、クエリがアクティブな間にプロセスが終了しないように、awaitTermination() を使用してクエリの終了を待つことにしました。
この例のコードを実際に実行するには、独自の Spark アプリケーション でコードをコンパイルするか、Spark をダウンロードしたら 例を実行するだけです。後者の方法を示します。まず、Netcat(ほとんどのUnixライクシステムにある小さなユーティリティ)をデータサーバーとして実行する必要があります。
$ nc -lk 9999
次に、別のターミナルで、次のコマンドを使用して例を開始できます。
$ ./bin/spark-submit examples/src/main/python/sql/streaming/structured_network_wordcount.py localhost 9999$ ./bin/run-example org.apache.spark.examples.sql.streaming.StructuredNetworkWordCount localhost 9999$ ./bin/run-example org.apache.spark.examples.sql.streaming.JavaStructuredNetworkWordCount localhost 9999$ ./bin/spark-submit examples/src/main/r/streaming/structured_network_wordcount.R localhost 9999その後、netcatサーバーを実行しているターミナルに入力されたどの行もカウントされ、1秒ごとに画面に表示されます。それは以下のようなものになります。
|
|
プログラミングモデル
Structured Streaming の鍵となる考え方は、ライブデータストリームを継続的に追加されるテーブルとして扱うことです。これにより、バッチ処理モデルに非常に似た新しいストリーム処理モデルが生まれます。静的テーブルに対する標準的なバッチライククエリとしてストリーミング計算を表現し、Spark はそれを アンバウンド 入力テーブルに対する 増分 クエリとして実行します。このモデルをより詳細に理解しましょう。
基本概念
入力データストリームを「入力テーブル」と見なします。ストリームで到着する各データ項目は、入力テーブルに追加される新しい行のようなものです。

入力に対するクエリは「結果テーブル」を生成します。各トリガー間隔(たとえば、1秒ごと)で、入力テーブルに新しい行が追加され、最終的に結果テーブルが更新されます。結果テーブルが更新されるたびに、変更された結果行を外部シンクに書き込みたいと考えます。
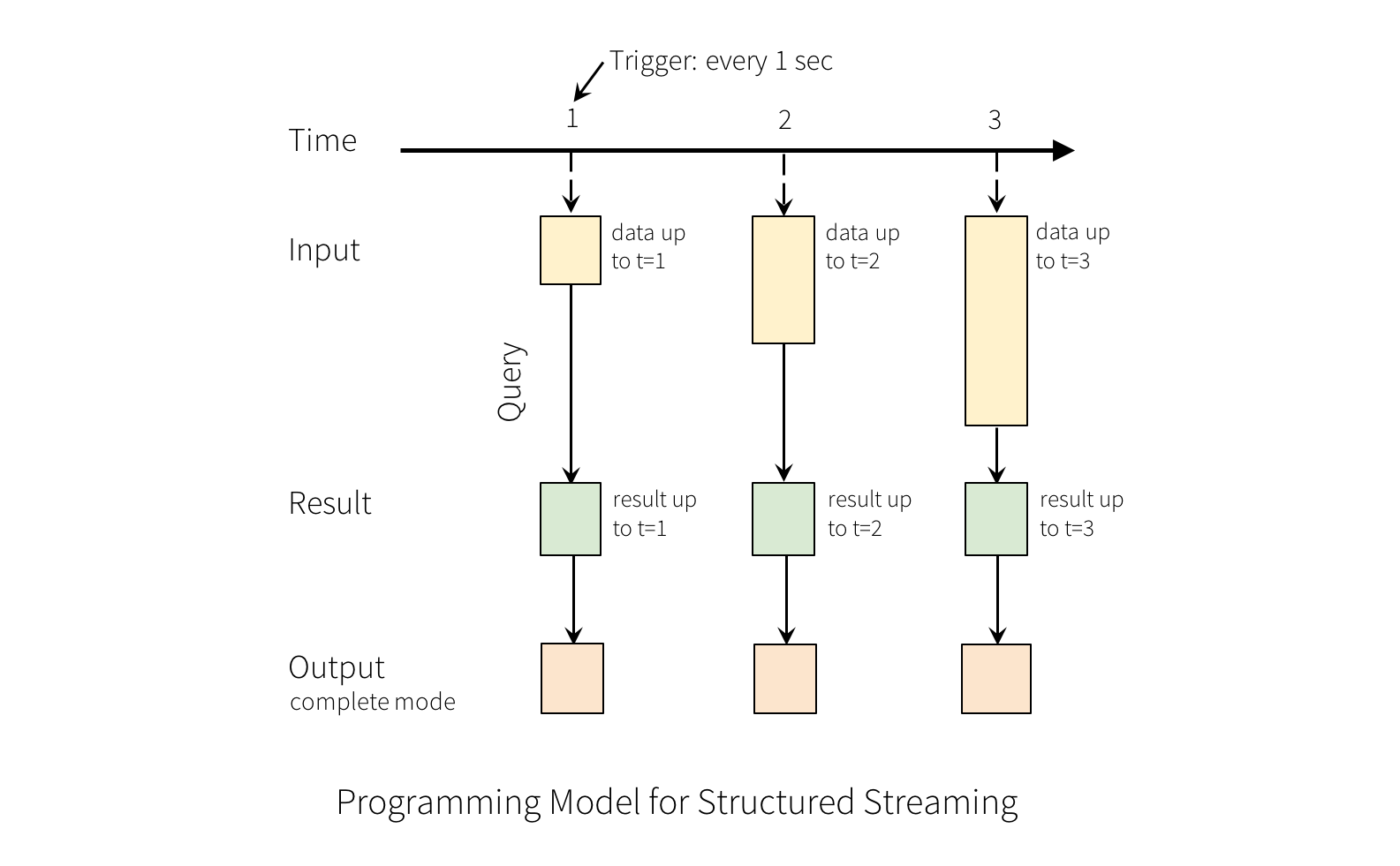
「出力」は、外部ストレージに書き込まれるものとして定義されます。出力は異なるモードで定義できます。
-
完全モード - 更新された結果テーブル全体が外部ストレージに書き込まれます。テーブル全体を書き込む処理は、ストレージコネクタに依存します。
-
追加モード - 前回のトリガー以降に結果テーブルに追加された新しい行のみが外部ストレージに書き込まれます。これは、結果テーブルの既存の行が変更されないと予想されるクエリにのみ適用されます。
-
更新モード - 前回のトリガー以降に結果テーブルで更新された行のみが外部ストレージに書き込まれます(Spark 2.1.1 以降で利用可能)。これは、このモードでは前回のトリガー以降に変更された行のみが出力されるという点で、完全モードとは異なります。クエリに集計が含まれていない場合、追加モードと同等になります。
各モードは特定の種類のクエリに適用されることに注意してください。これは 後ほど詳しく説明します。
このモデルの使用法を説明するために、上記の 簡単な例 の文脈でモデルを理解しましょう。最初の lines DataFrame は入力テーブルであり、最後の wordCounts DataFrame は結果テーブルです。ストリーミング lines DataFrame に対する wordCounts を生成するためのクエリは、静的 DataFrame の場合と同じであることに注意してください。しかし、このクエリが開始されると、Spark はソケット接続からの新しいデータを継続的にチェックします。新しいデータがある場合、Spark は「増分」クエリを実行し、前の実行中のカウントと新しいデータを組み合わせて更新されたカウントを計算します。これは以下に示すとおりです。
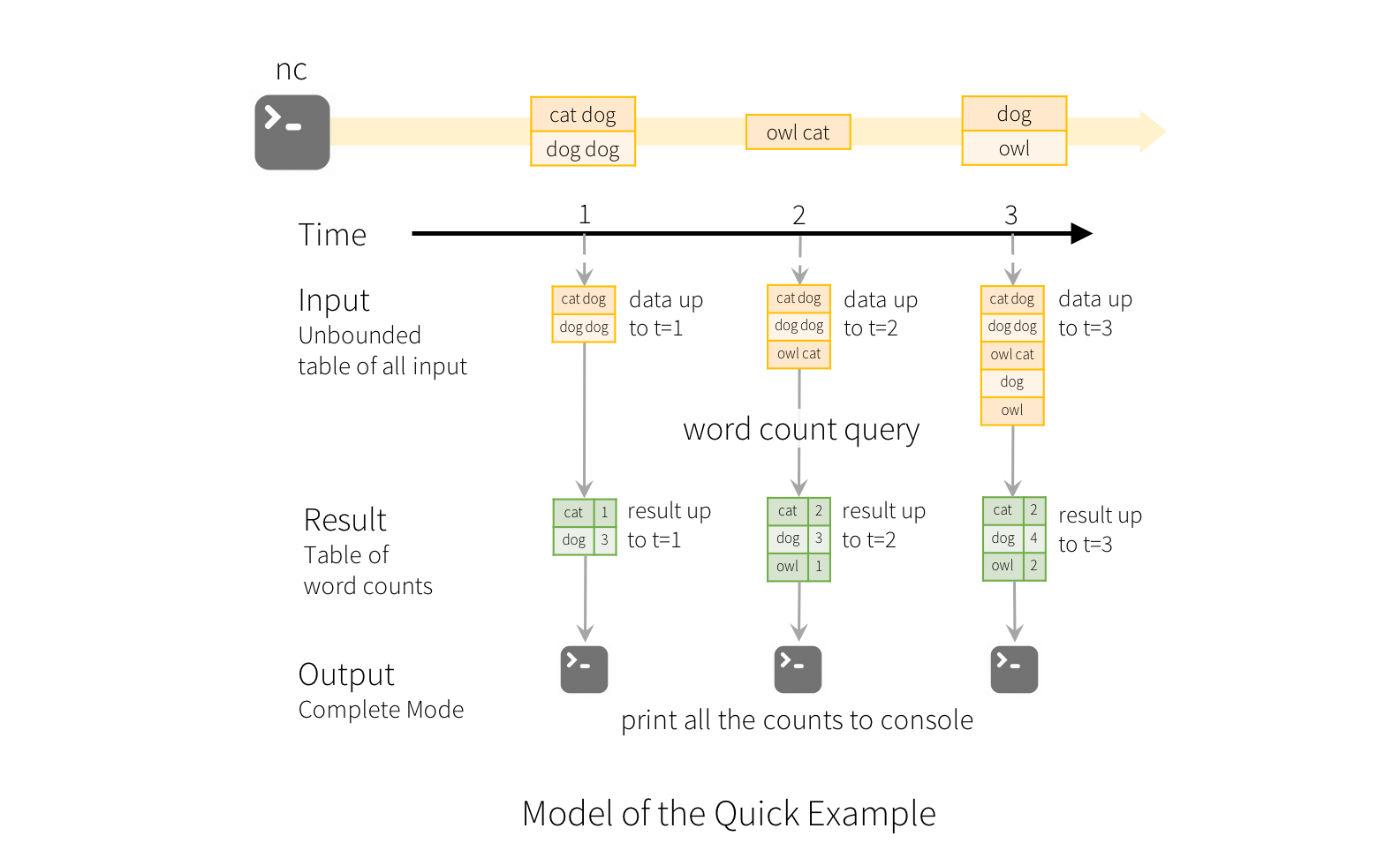
Structured Streaming はテーブル全体を具現化しないことに注意してください。 最新の利用可能なデータをストリーミングデータソースから読み取り、増分的に処理して結果を更新し、ソースデータを破棄します。結果を更新するために必要な最小限の中間 状態 データのみを保持します(たとえば、前の例の中間カウント)。
このモデルは、他の多くのストリーム処理エンジンとは大きく異なります。多くのストリーミングシステムでは、ユーザーが実行中の集計を自分で維持する必要があり、フォールトトレランスとデータの一貫性(少なくとも1回、最大1回、または正確に1回)について考慮する必要があります。このモデルでは、Spark が新しいデータがあるときに結果テーブルを更新する責任を負うため、ユーザーはそれについて考慮する必要がなくなります。例として、このモデルがイベントタイムベースの処理と遅延到着データをどのように処理するかを見てみましょう。
イベントタイムと遅延データの処理
イベントタイムとは、データ自体に埋め込まれた時間です。多くのアプリケーションでは、このイベントタイムに基づいて操作したい場合があります。たとえば、IoT デバイスが毎分生成したイベント数を取得したい場合、Spark がそれらを受信する時間(つまり、データ内のイベントタイム)ではなく、データが生成された時間を使用する可能性が高いです。このイベントタイムは、このモデルで非常に自然に表現されます。デバイスからの各イベントはテーブルの行であり、イベントタイムはその行の値です。これにより、ウィンドウベースの集計(たとえば、毎分のイベント数)は、イベントタイム列のグループ化と集計の特別なタイプになります。各タイムウィンドウはグループであり、各行は複数のウィンドウ/グループに属することができます。したがって、このようなイベントタイムウィンドウベースの集計クエリは、静的データセット(たとえば、収集されたデバイスイベントログから)とデータストリームの両方で一貫して定義でき、ユーザーの作業を大幅に容易にします。
さらに、このモデルは、イベントタイムに基づいて予想よりも遅れて到着したデータを自然に処理します。Spark は結果テーブルを更新しているため、遅延データがある場合に古い集計を更新し、古い集計をクリーンアップして中間状態データのサイズを制限するための完全な制御を行っています。Spark 2.1 以降、ウォーターマーキングをサポートしており、ユーザーは遅延データのしきい値を指定でき、エンジンがそれに応じて古い状態をクリーンアップできるようになります。これらは、ウィンドウ操作セクションで後ほど詳しく説明します。
フォールトトレランスセマンティクス
エンドツーエンドで正確に1回セマンティクスを提供することは、Structured Streaming の設計の主要な目標の1つでした。これを達成するために、Structured Streaming のソース、シンク、および実行エンジンは、処理の正確な進行状況を確実に追跡できるように設計されており、再起動や再処理によってあらゆる種類の障害を処理できます。各ストリーミングソースには、ストリーム内の読み取り位置を追跡するためのオフセット(Kafka オフセットや Kinesis シーケンス番号に似ています)があると想定されます。エンジンは、チェックポインティングとライトアヘッドログを使用して、各トリガーで処理されるデータのオフセット範囲を記録します。ストリーミングシンクは、再処理を処理するために冪等になるように設計されています。これらを組み合わせることで、再生可能なソースと冪等なシンクを使用することにより、Structured Streaming はあらゆる障害下で エンドツーエンドで正確に1回セマンティクス を保証できます。