Structured Streaming プログラミングガイド
Dataset と DataFrame を使用した API
Spark 2.0 以降、DataFrame と Dataset は、静的で有限なデータだけでなく、ストリーミングで無制限なデータも表現できます。静的な Dataset/DataFrame と同様に、共通のエントリポイントである SparkSession (Python/Scala/Java/R ドキュメント) を使用して、ストリーミングソースからストリーミング DataFrame/Dataset を作成し、静的な DataFrame/Dataset と同じ操作を適用できます。Dataset/DataFrame に慣れていない場合は、DataFrame/Dataset プログラミングガイド を参照して習熟することを強くお勧めします。
ストリーミング DataFrame およびストリーミング Dataset の作成
ストリーミング DataFrame は、SparkSession.readStream() から返される DataStreamReader インターフェース (Python/Scala/Java ドキュメント) を通じて作成できます。 R では、read.stream() メソッドを使用します。静的な DataFrame を作成するための read インターフェースと同様に、ソースの詳細(データ形式、スキーマ、オプションなど)を指定できます。
入力ソース
いくつかの組み込みソースがあります。
- ファイルソース - ディレクトリに書き込まれたファイルをデータのストリームとして読み取ります。ファイルはファイル変更時間の順に処理されます。
latestFirstが設定されている場合、順序は逆になります。サポートされているファイル形式は、text、CSV、JSON、ORC、Parquet です。より最新のリストと各ファイル形式でサポートされているオプションについては、DataStreamReader インターフェースのドキュメントを参照してください。ファイルは、ほとんどのファイルシステムでファイル移動操作によって実現できる、アトミックな方法で指定されたディレクトリに配置する必要があることに注意してください。 -
Kafka ソース - Kafka からデータを読み取ります。Kafka ブローカーバージョン 0.10.0 以降と互換性があります。詳細については、Kafka 統合ガイド を参照してください。
-
ソケットソース (テスト用) - ソケット接続から UTF8 テキストデータを読み取ります。リスニングサーバーソケットはドライバーにあります。これはエンドツーエンドの耐障害性保証を提供しないため、テストにのみ使用する必要があることに注意してください。
-
レートソース (テスト用) - 指定された行数/秒でデータを生成します。各出力行には、
timestampとvalueが含まれます。timestampはメッセージ発行時刻を含むTimestamp型であり、valueはメッセージ数を表すLong型で、最初の行から 0 から始まります。このソースはテストおよびベンチマークを目的としています。 - マイクロバッチあたりのレートソース (テスト用) - 指定された行数/マイクロバッチでデータを生成します。各出力行には、
timestampとvalueが含まれます。timestampはメッセージ発行時刻を含むTimestamp型であり、valueはメッセージ数を表すLong型で、最初の行から 0 から始まります。rateデータソースとは異なり、このデータソースは、トリガーの構成、クエリの遅延など、クエリの実行に関係なく、マイクロバッチごとに一貫した入力行のセットを提供します。たとえば、バッチ 0 は 0〜999 を生成し、バッチ 1 は 1000〜1999 を生成します。生成される時間も同様です。このソースはテストおよびベンチマークを目的としています。
一部のソースは、障害発生後にチェックポイントされたオフセットを使用してデータを再利用できないため、耐障害性がありません。以前のセクション 耐障害性セマンティクス を参照してください。Spark のすべてのソースの詳細を以下に示します。
| ソース | オプション | 耐障害性 | 注記 |
|---|---|---|---|
| ファイルソース |
path: 入力ディレクトリへのパス。すべてのファイル形式に共通です。maxFilesPerTrigger: 各トリガーで考慮される新しいファイルの最大数 (デフォルト: 最大なし)maxBytesPerTrigger: 各トリガーで考慮される新しいファイルの合計最大サイズ (デフォルト: 最大なし)。maxBytesPerTrigger と maxFilesPerTrigger は同時に設定できません。いずれか一方を選択する必要があります。ストリームは常に少なくとも 1 つのファイルを読み取るため、進行でき、指定された最大値よりも大きいファイルでスタックしないことに注意してください。latestFirst: 最新の新しいファイルを最初に処理するかどうか。大量のファイルバックログがある場合に役立ちます (デフォルト: false)fileNameOnly: ファイル名のみに基づいて新しいファイルを確認するか、完全なパスに基づいて確認するかどうか (デフォルト: false)。これを `true` に設定すると、次のファイルは、ファイル名が同じであるため、同じファイルと見なされます。"file:///dataset.txt" "s3://a/dataset.txt" "s3n://a/b/dataset.txt" "s3a://a/b/c/dataset.txt" maxFileAge: ディレクトリ内で見つかるファイルの最大年齢。それ以降は無視されます。最初のバッチでは、すべてのファイルが有効と見なされます。latestFirst が `true` に設定され、maxFilesPerTrigger または maxBytesPerTrigger が設定されている場合、このパラメーターは無視されます。これは、有効で処理されるべき古いファイルが無視される可能性があるためです。最大年齢は、現在のシステム時刻ではなく、最新のファイルのタイムスタンプに対して指定されます。(デフォルト: 1 週間)maxCachedFiles: 後続のバッチで処理するためにキャッシュするファイルの最大数 (デフォルト: 10000)。ファイルがキャッシュで利用可能な場合、入力ソースからのリストよりも先にキャッシュから読み取られます。discardCachedInputRatio: 入力ソースからのリストを許可するキャッシュされたファイル/バイトの割合と、最大ファイル/バイトの比率。キャッシュされた入力が読み取り可能な量よりも少ない場合 (デフォルト: 0.2)。たとえば、バッチ用に 10 個のキャッシュされたファイルしか残っていないが、maxFilesPerTrigger が 100 に設定されている場合、10 個のキャッシュされたファイルは破棄され、新しいリストが実行されます。同様に、バッチ用に 10MB のキャッシュされたファイルが残っているが、maxBytesPerTrigger が 100MB に設定されている場合、キャッシュされたファイルは破棄されます。cleanSource: 処理後に完了したファイルをクリーンアップするためのオプション。利用可能なオプションは「archive」、「delete」、「off」です。オプションが指定されていない場合、デフォルト値は「off」です。 「archive」が指定されている場合、追加オプション sourceArchiveDir も指定する必要があります。 「sourceArchiveDir」の値は、ソースパターンの深さ (ルートディレクトリからのディレクトリ数) と一致してはなりません。深さは、両方のパスの深さの最小値です。これにより、アーカイブされたファイルが新しいソースファイルとして含まれないことが保証されます。たとえば、`/hello?/spark/*` をソースパターンとして提供した場合、`/hello1/spark/archive/dir` は `/hello?/spark/*` と `/hello1/spark/archive` が一致するため、`sourceArchiveDir` の値として使用できません。`/hello1/spark` も `/hello?/spark` と `/hello1/spark` が一致するため、`sourceArchiveDir` の値として使用できません。`/archived/here` は一致しないため、OK です。 Spark は、ソースファイルのパスを尊重して、ソースファイルを移動します。たとえば、ソースファイルのパスが /a/b/dataset.txt で、アーカイブディレクトリのパスが /archived/here の場合、ファイルは /archived/here/a/b/dataset.txt に移動されます。注意: アーカイブ (移動による) および完了したファイルの削除は、オーバーヘッドを伴います (別のスレッドで実行されている場合でも、遅くなります)。そのため、このオプションを有効にする前に、ファイルシステムでの各操作のコストを理解する必要があります。一方、このオプションを有効にすると、高価な操作であるソースファイルのリストのコストが削減されます。 完了したファイルクリーナーで使用されるスレッド数は、 spark.sql.streaming.fileSource.cleaner.numThreads (デフォルト: 1) で構成できます。注意 2: このオプションを有効にすると、ソースパスは複数のソースまたはクエリから使用しないでください。同様に、ソースパスがファイルストリームシンクの出力ディレクトリのいずれかのファイルと一致しないことを確認する必要があります。 注意 3: 削除および移動アクションは、最善の努力です。ファイルの削除または移動に失敗しても、ストリーミングクエリは失敗しません。Spark は、アプリケーションが正常にシャットダウンしない、クリーンアップするためにキューに入れられたファイルが多すぎるなどの状況で、一部のソースファイルをクリーンアップしない場合があります。 ファイル形式固有のオプションについては、 DataStreamReader の関連メソッドを参照してください (Python/Scala/Java/R)。たとえば、「parquet」形式のオプションについては、DataStreamReader.parquet() を参照してください。さらに、特定のファイル形式に影響を与えるセッション構成があります。詳細については、SQL プログラミングガイド を参照してください。たとえば、「parquet」については、Parquet 設定 セクションを参照してください。 |
はい | グロブパスをサポートしますが、複数のコンマ区切りのパス/グロブはサポートしません。 |
| ソケットソース |
host: 接続先のホスト。指定する必要がありますport: 接続先のポート。指定する必要があります |
いいえ | |
| レートソース |
rowsPerSecond (例: 100, デフォルト: 1): 1 秒あたりに生成される行数。rampUpTime (例: 5s, デフォルト: 0s): 生成速度が rowsPerSecond になるまでのランプアップ時間。秒よりも細かい粒度を使用すると、整数秒に切り捨てられます。numPartitions (例: 10, デフォルト: Spark のデフォルト並列度): 生成される行のパーティション数。ソースは rowsPerSecond に達するように最善を尽くしますが、クエリはリソースに制約される可能性があり、numPartitions を調整して目的の速度に達するのに役立ちます。 |
はい | |
| マイクロバッチあたりのレートソース (形式: rate-micro-batch) |
rowsPerBatch (例: 100): マイクロバッチあたりに生成される行数。numPartitions (例: 10, デフォルト: Spark のデフォルト並列度): 生成される行のパーティション数。startTimestamp (例: 1000, デフォルト: 0): 生成される時間の開始値。advanceMillisPerBatch (例: 1000, デフォルト: 1000): 各マイクロバッチで生成される時間にどれだけ時間が進むか。 |
はい | |
| Kafka ソース | 「Kafka 統合ガイド」を参照してください。 | はい | |
以下に例を示します。
spark = SparkSession. ...
# Read text from socket
socketDF = spark \
.readStream \
.format("socket") \
.option("host", "localhost") \
.option("port", 9999) \
.load()
socketDF.isStreaming() # Returns True for DataFrames that have streaming sources
socketDF.printSchema()
# Read all the csv files written atomically in a directory
userSchema = StructType().add("name", "string").add("age", "integer")
csvDF = spark \
.readStream \
.option("sep", ";") \
.schema(userSchema) \
.csv("/path/to/directory") # Equivalent to format("csv").load("/path/to/directory")val spark: SparkSession = ...
// Read text from socket
val socketDF = spark
.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()
socketDF.isStreaming // Returns True for DataFrames that have streaming sources
socketDF.printSchema
// Read all the csv files written atomically in a directory
val userSchema = new StructType().add("name", "string").add("age", "integer")
val csvDF = spark
.readStream
.option("sep", ";")
.schema(userSchema) // Specify schema of the csv files
.csv("/path/to/directory") // Equivalent to format("csv").load("/path/to/directory")SparkSession spark = ...
// Read text from socket
Dataset<Row> socketDF = spark
.readStream()
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load();
socketDF.isStreaming(); // Returns True for DataFrames that have streaming sources
socketDF.printSchema();
// Read all the csv files written atomically in a directory
StructType userSchema = new StructType().add("name", "string").add("age", "integer");
Dataset<Row> csvDF = spark
.readStream()
.option("sep", ";")
.schema(userSchema) // Specify schema of the csv files
.csv("/path/to/directory"); // Equivalent to format("csv").load("/path/to/directory")sparkR.session(...)
# Read text from socket
socketDF <- read.stream("socket", host = hostname, port = port)
isStreaming(socketDF) # Returns TRUE for SparkDataFrames that have streaming sources
printSchema(socketDF)
# Read all the csv files written atomically in a directory
schema <- structType(structField("name", "string"),
structField("age", "integer"))
csvDF <- read.stream("csv", path = "/path/to/directory", schema = schema, sep = ";")これらの例は、型指定されていないストリーミング DataFrame を生成します。これは、DataFrame のスキーマがコンパイル時にチェックされず、クエリが送信されるときに実行時にのみチェックされることを意味します。map、flatMap などの一部の操作は、コンパイル時に型がわかっている必要があります。これらの操作を行うには、静的な DataFrame と同じ方法を使用して、これらの型指定されていないストリーミング DataFrame を型指定されたストリーミング Dataset に変換できます。詳細については、「SQL プログラミングガイド」を参照してください。さらに、サポートされているストリーミング ソースの詳細については、後述します。
Spark 3.1 以降では、DataStreamReader.table() を使用してテーブルからストリーミング DataFrame を作成することもできます。詳細については、「ストリーミングテーブル API」を参照してください。
ストリーミング DataFrame/Dataset のスキーマ推論とパーティショニング
デフォルトでは、ファイルベースのソースからの構造化ストリーミングは、Spark が自動的に推論するのではなく、スキーマを指定する必要があります。この制限により、障害発生時でも、ストリーミングクエリに一貫したスキーマが使用されることが保証されます。アドホックなユースケースでは、spark.sql.streaming.schemaInference を true に設定することで、スキーマ推論を再度有効にできます。
サブディレクトリが /key=value/ という名前で存在し、リストがこれらのディレクトリに自動的に再帰する場合、パーティション検出が行われます。これらの列がユーザー提供のスキーマに存在する場合、Spark によって、読み取られるファイルのパスに基づいて入力されます。パーティションスキームを構成するディレクトリは、クエリが開始されるときに存在し、静的である必要があります。たとえば、`/data/year=2015/` が存在する場合に `/data/year=2016/` を追加することは問題ありませんが、ディレクトリ `/data/date=2016-04-17/` を作成することによってパーティション列を変更することは無効です。
ストリーミング DataFrame/Dataset の操作
型指定されていない SQL ライクな操作 (例: select、where、groupBy) から、型指定された RDD ライクな操作 (例: map、filter、flatMap) まで、あらゆる種類の操作をストリーミング DataFrame/Dataset に適用できます。詳細については、「SQL プログラミングガイド」を参照してください。使用できる操作の例をいくつか見てみましょう。
基本操作 - 選択、射影、集計
DataFrame/Dataset のほとんどの一般的な操作はストリーミングでサポートされています。サポートされていない操作は、このセクションの 後 で説明します。
df = ... # streaming DataFrame with IOT device data with schema { device: string, deviceType: string, signal: double, time: DateType }
# Select the devices which have signal more than 10
df.select("device").where("signal > 10")
# Running count of the number of updates for each device type
df.groupBy("deviceType").count()case class DeviceData(device: String, deviceType: String, signal: Double, time: DateTime)
val df: DataFrame = ... // streaming DataFrame with IOT device data with schema { device: string, deviceType: string, signal: double, time: string }
val ds: Dataset[DeviceData] = df.as[DeviceData] // streaming Dataset with IOT device data
// Select the devices which have signal more than 10
df.select("device").where("signal > 10") // using untyped APIs
ds.filter(_.signal > 10).map(_.device) // using typed APIs
// Running count of the number of updates for each device type
df.groupBy("deviceType").count() // using untyped API
// Running average signal for each device type
import org.apache.spark.sql.expressions.scalalang.typed
ds.groupByKey(_.deviceType).agg(typed.avg(_.signal)) // using typed APIimport org.apache.spark.api.java.function.*;
import org.apache.spark.sql.*;
import org.apache.spark.sql.expressions.javalang.typed;
import org.apache.spark.sql.catalyst.encoders.ExpressionEncoder;
public class DeviceData {
private String device;
private String deviceType;
private Double signal;
private java.sql.Date time;
...
// Getter and setter methods for each field
}
Dataset<Row> df = ...; // streaming DataFrame with IOT device data with schema { device: string, type: string, signal: double, time: DateType }
Dataset<DeviceData> ds = df.as(ExpressionEncoder.javaBean(DeviceData.class)); // streaming Dataset with IOT device data
// Select the devices which have signal more than 10
df.select("device").where("signal > 10"); // using untyped APIs
ds.filter((FilterFunction<DeviceData>) value -> value.getSignal() > 10)
.map((MapFunction<DeviceData, String>) value -> value.getDevice(), Encoders.STRING());
// Running count of the number of updates for each device type
df.groupBy("deviceType").count(); // using untyped API
// Running average signal for each device type
ds.groupByKey((MapFunction<DeviceData, String>) value -> value.getDeviceType(), Encoders.STRING())
.agg(typed.avg((MapFunction<DeviceData, Double>) value -> value.getSignal()));df <- ... # streaming DataFrame with IOT device data with schema { device: string, deviceType: string, signal: double, time: DateType }
# Select the devices which have signal more than 10
select(where(df, "signal > 10"), "device")
# Running count of the number of updates for each device type
count(groupBy(df, "deviceType"))ストリーミング DataFrame/Dataset を一時ビューとして登録し、SQL コマンドを適用することもできます。
df.createOrReplaceTempView("updates")
spark.sql("select count(*) from updates") # returns another streaming DFdf.createOrReplaceTempView("updates")
spark.sql("select count(*) from updates") // returns another streaming DFdf.createOrReplaceTempView("updates");
spark.sql("select count(*) from updates"); // returns another streaming DFcreateOrReplaceTempView(df, "updates")
sql("select count(*) from updates")DataFrame/Dataset にストリーミングデータが含まれているかどうかは、df.isStreaming を使用して識別できることに注意してください。
df.isStreaming()df.isStreamingdf.isStreaming()isStreaming(df)クエリプランを確認することをお勧めします。Spark は、ストリーミング Dataset に対する SQL ステートメントの解釈中にステートフルな操作を挿入する可能性があります。クエリプランにステートフルな操作が挿入されたら、ステートフルな操作に関する考慮事項 (例: 出力モード、ウォーターマーク、ステートストアのサイズ管理など) を考慮してクエリを確認する必要があります。
イベントタイムでのウィンドウ操作
イベントタイムでのスライディングウィンドウによる集計は、構造化ストリーミングでは簡単で、グループ化された集計と非常によく似ています。グループ化された集計では、ユーザー指定のグループ化列の各一意の値に対して集計値 (例: カウント) が維持されます。ウィンドウベースの集計の場合、集計値は、行のイベントタイムが属する各ウィンドウに対して維持されます。これを例で理解しましょう。
たとえば、クイック例 を変更し、ストリームにラインとラインが生成された時刻が含まれるとします。単語カウントを実行する代わりに、10 分間のウィンドウ内で単語をカウントし、5 分ごとに更新したいとします。つまり、12:00~12:10、12:05~12:15、12:10~12:20 などの 10 分間のウィンドウ内の単語カウントです。12:00~12:10 は、12:00 以降 12:10 より前に受信したデータを意味します。ここで、12:07 に受信された単語を考えてみましょう。この単語は、2 つのウィンドウ、12:00~12:10 と 12:05~12:15 に対応するカウントをインクリメントする必要があります。したがって、カウントは、グループ化キー (つまり、単語) とウィンドウ (イベントタイムから計算可能) の両方によってインデックス付けされます。
結果テーブルは、次のようなものになります。
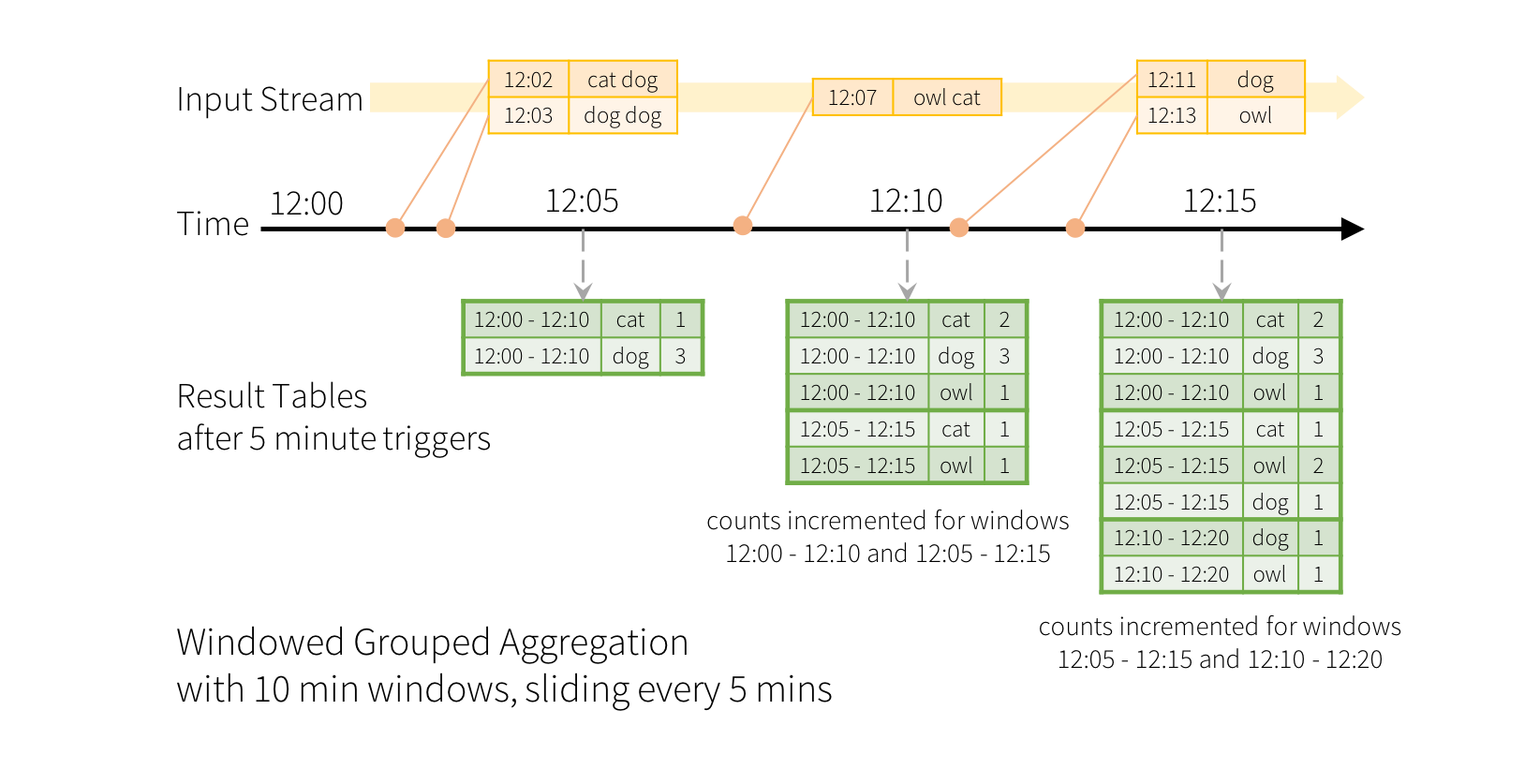
このウィンドウ処理はグループ化に似ているため、コードでは groupBy() および window() 操作を使用してウィンドウ化された集計を表現できます。以下の例の完全なコードは、Python/Scala/Java で確認できます。
words = ... # streaming DataFrame of schema { timestamp: Timestamp, word: String }
# Group the data by window and word and compute the count of each group
windowedCounts = words.groupBy(
window(words.timestamp, "10 minutes", "5 minutes"),
words.word
).count()import spark.implicits._
val words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String }
// Group the data by window and word and compute the count of each group
val windowedCounts = words.groupBy(
window($"timestamp", "10 minutes", "5 minutes"),
$"word"
).count()Dataset<Row> words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String }
// Group the data by window and word and compute the count of each group
Dataset<Row> windowedCounts = words.groupBy(
functions.window(words.col("timestamp"), "10 minutes", "5 minutes"),
words.col("word")
).count();words <- ... # streaming DataFrame of schema { timestamp: Timestamp, word: String }
# Group the data by window and word and compute the count of each group
windowedCounts <- count(
groupBy(
words,
window(words$timestamp, "10 minutes", "5 minutes"),
words$word))遅延データの処理とウォーターマーキング
ここで、イベントの 1 つがアプリケーションに遅れて到着した場合に何が起こるかを考えてみましょう。たとえば、12:04 (イベントタイム) に生成された単語が、12:11 にアプリケーションで受信されたとします。アプリケーションは、ウィンドウ 12:00 - 12:10 の古いカウントを更新するために、12:11 ではなく 12:04 という時刻を使用する必要があります。これは、ウィンドウベースのグループ化で自然に発生します。構造化ストリーミングは、部分的な集計の中間状態を長期間維持できるため、遅延データが古いウィンドウの集計を正しく更新できます。これは以下に示されています。
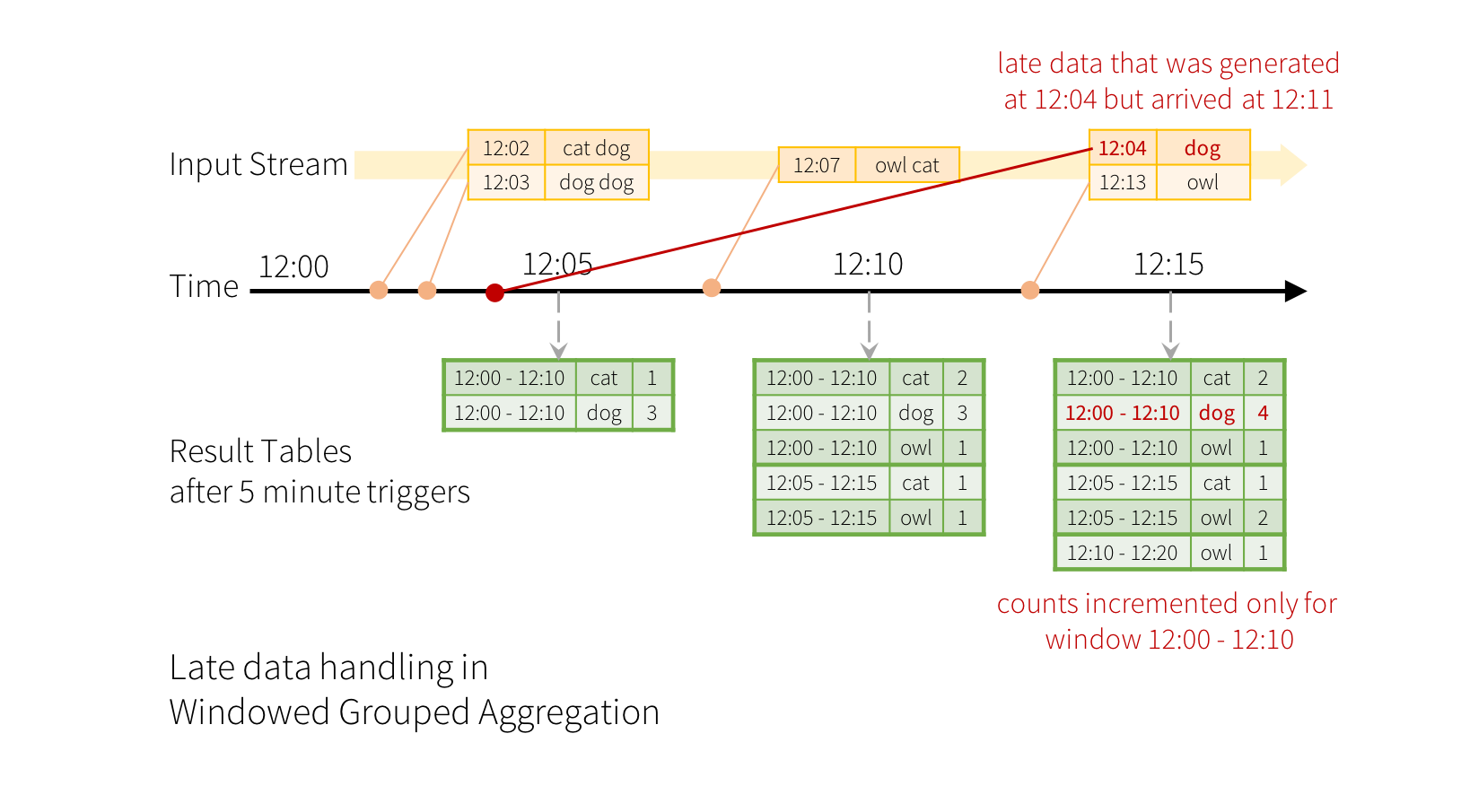
しかし、このクエリを数日間実行するには、システムがメモリ内に蓄積される中間状態の量を制限する必要があります。これは、システムが、アプリケーションがその集計に対する遅延データを受信しなくなるため、古い集計をメモリ内状態からいつ削除できるかを知る必要があることを意味します。これを可能にするために、Spark 2.1 では、エンジンがデータの現在のイベントタイムを自動的に追跡し、それに応じて古い状態をクリーンアップしようとする**ウォーターマーキング**が導入されました。クエリのウォーターマークは、イベントタイム列と、イベントタイムの観点からデータがどれだけ遅延すると予想されるかのしきい値を指定することによって定義できます。時刻 T で終了する特定のウィンドウについて、エンジンは状態を維持し、状態を更新する遅延データを (エンジンによって検出された最大イベントタイム - 遅延しきい値 > T) まで許可します。言い換えると、しきい値内の遅延データは集計されますが、しきい値よりも遅いデータは破棄され始めます (セマンティクスについては、このセクションの 後 を参照してください)。例で理解しましょう。以下に示すように、withWatermark() を使用して、前の例で簡単にウォーターマーキングを定義できます。
words = ... # streaming DataFrame of schema { timestamp: Timestamp, word: String }
# Group the data by window and word and compute the count of each group
windowedCounts = words \
.withWatermark("timestamp", "10 minutes") \
.groupBy(
window(words.timestamp, "10 minutes", "5 minutes"),
words.word) \
.count()import spark.implicits._
val words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String }
// Group the data by window and word and compute the count of each group
val windowedCounts = words
.withWatermark("timestamp", "10 minutes")
.groupBy(
window($"timestamp", "10 minutes", "5 minutes"),
$"word")
.count()Dataset<Row> words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String }
// Group the data by window and word and compute the count of each group
Dataset<Row> windowedCounts = words
.withWatermark("timestamp", "10 minutes")
.groupBy(
window(col("timestamp"), "10 minutes", "5 minutes"),
col("word"))
.count();words <- ... # streaming DataFrame of schema { timestamp: Timestamp, word: String }
# Group the data by window and word and compute the count of each group
words <- withWatermark(words, "timestamp", "10 minutes")
windowedCounts <- count(
groupBy(
words,
window(words$timestamp, "10 minutes", "5 minutes"),
words$word))この例では、クエリのウォーターマークを「timestamp」列の値に定義し、「10 分」をデータが遅延する可能性のあるしきい値として定義しています。このクエリが Update 出力モード (後述の 出力モード セクションで説明) で実行される場合、エンジンはウィンドウがウォーターマークよりも古くなるまで、結果テーブルでウィンドウのカウントを更新し続けます。ウォーターマークは、「timestamp」列の現在のイベントタイムよりも 10 分遅れています。以下に例を示します。
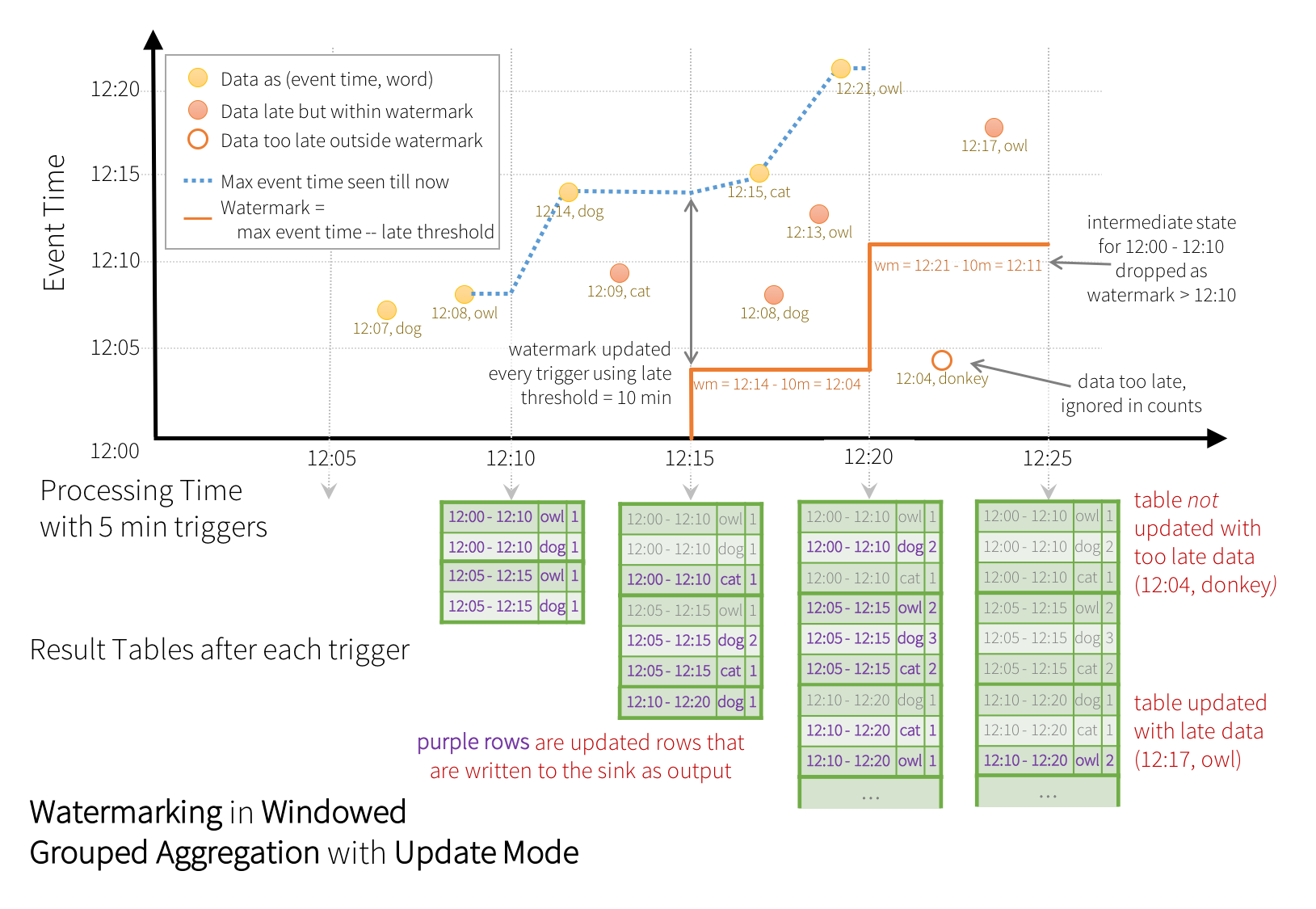
図に示すように、エンジンによって追跡される最大イベントタイムは青い破線であり、各トリガーの開始時に設定されるウォーターマークは、(最大イベントタイム - '10 分') であり、赤い線です。たとえば、エンジンがデータ (12:14, dog) を検出すると、次のトリガーのウォーターマークは 12:04 に設定されます。このウォーターマークにより、エンジンは追加の 10 分間、中間状態を維持して、遅延データがカウントされるようになります。たとえば、データ (12:09, cat) は順序が狂っていて遅延しており、ウィンドウ 12:00 - 12:10 と 12:05 - 12:15 に属します。これは、トリガー内のウォーターマーク 12:04 よりもまだ前にあるため、エンジンは中間カウントを状態として維持し、関連するウィンドウのカウントを正しく更新します。ただし、ウォーターマークが 12:11 に更新されると、ウィンドウ (12:00 - 12:10) の中間状態がクリアされ、それ以降のすべてのデータ (例: (12:04, donkey)) は「遅すぎる」と見なされ、無視されます。各トリガーの後、更新されたカウント (つまり、紫色の行) が、Update モードによって指示されるように、シンクに書き込まれることに注意してください。
一部のシンク (例: ファイル) は、Update モードが必要とするきめ細かな更新をサポートしていない場合があります。それらと連携するために、Append モードもサポートしています。ここでは、最終カウントのみがシンクに書き込まれます。これは以下に示されています。
非ストリーミング Dataset で withWatermark を使用しても、効果はありません。ウォーターマークはバッチクエリに影響を与えないため、直接無視されます。
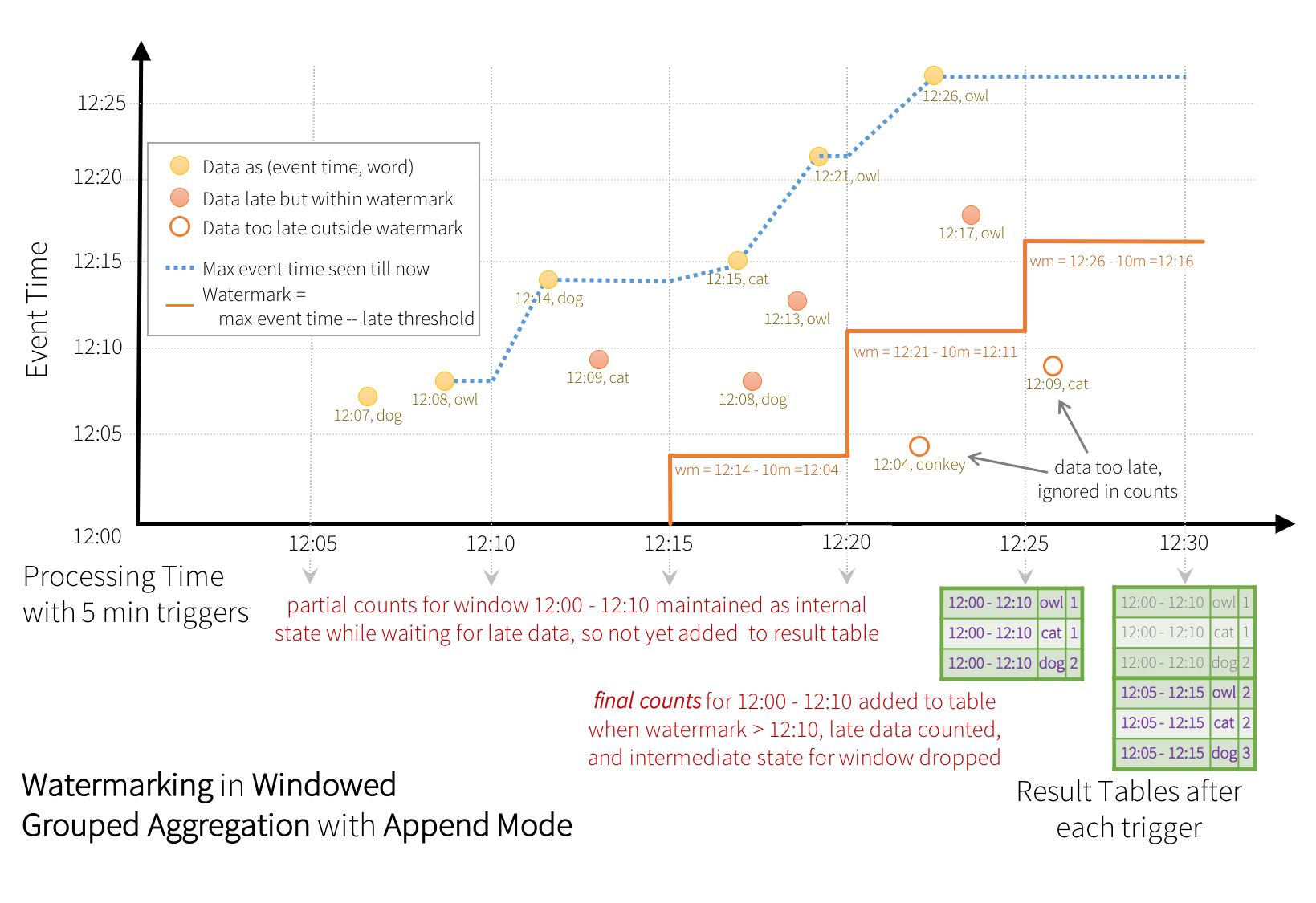
以前の Update モードと同様に、エンジンは各ウィンドウの中間カウントを維持します。ただし、部分的なカウントは結果テーブルに更新されず、シンクに書き込まれません。エンジンは遅延データがカウントされるのを「10 分」待ってから、ウォーターマークよりも古いウィンドウの中間状態を削除し、最終カウントを結果テーブル/シンクに追加します。たとえば、ウィンドウ 12:00 - 12:10 の最終カウントは、ウォーターマークが 12:11 に更新された後にのみ結果テーブルに追加されます。
時間ウィンドウの種類
Spark は、タンブリング (固定)、スライディング、セッションの 3 種類的时间ウィンドウをサポートしています。
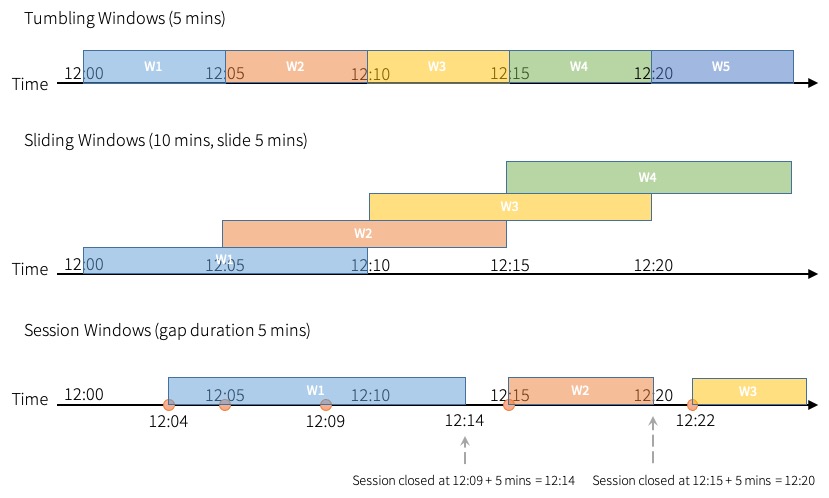
タンブリングウィンドウは、固定サイズの非オーバーラップする連続した時間間隔のシリーズです。入力は 1 つのウィンドウにのみバインドできます。
スライディングウィンドウは、タンブリングウィンドウと同様に「固定サイズ」ですが、ウィンドウの期間よりスライドの期間が短い場合、ウィンドウはオーバーラップする可能性があり、この場合、入力は複数のウィンドウにバインドできます。
タンブリングおよびスライディングウィンドウは、window 関数を使用します。これは上記の例で説明されています。
セッションウィンドウは、前の 2 つのタイプとは異なる特性を持っています。セッションウィンドウは、入力に応じて、ウィンドウ長の動的なサイズを持ちます。セッションウィンドウは入力で開始し、ギャップ期間内に後続の入力が受信された場合、自身を拡張します。静的なギャップ期間の場合、セッションウィンドウは、最新の入力を受信した後、ギャップ期間内に受信される入力がない場合に閉じます。
セッションウィンドウは session_window 関数を使用します。この関数の使用法は、window 関数の使用法に似ています。
events = ... # streaming DataFrame of schema { timestamp: Timestamp, userId: String }
# Group the data by session window and userId, and compute the count of each group
sessionizedCounts = events \
.withWatermark("timestamp", "10 minutes") \
.groupBy(
session_window(events.timestamp, "5 minutes"),
events.userId) \
.count()import spark.implicits._
val events = ... // streaming DataFrame of schema { timestamp: Timestamp, userId: String }
// Group the data by session window and userId, and compute the count of each group
val sessionizedCounts = events
.withWatermark("timestamp", "10 minutes")
.groupBy(
session_window($"timestamp", "5 minutes"),
$"userId")
.count()Dataset<Row> events = ... // streaming DataFrame of schema { timestamp: Timestamp, userId: String }
// Group the data by session window and userId, and compute the count of each group
Dataset<Row> sessionizedCounts = events
.withWatermark("timestamp", "10 minutes")
.groupBy(
session_window(col("timestamp"), "5 minutes"),
col("userId"))
.count();静的値の代わりに、式を提供して、入力行に基づいてギャップ期間を動的に指定することもできます。負またはゼロのギャップ期間を持つ行は、集計からフィルターされることに注意してください。
動的なギャップ期間を使用すると、セッションウィンドウの終了は最新の入力に依存しなくなります。セッションウィンドウの範囲は、クエリの実行中にイベントの開始時刻と評価されたギャップ期間によって決定されるすべてのイベントの範囲の和集合です。
from pyspark.sql import functions as sf
events = ... # streaming DataFrame of schema { timestamp: Timestamp, userId: String }
session_window = session_window(events.timestamp, \
sf.when(events.userId == "user1", "5 seconds") \
.when(events.userId == "user2", "20 seconds").otherwise("5 minutes"))
# Group the data by session window and userId, and compute the count of each group
sessionizedCounts = events \
.withWatermark("timestamp", "10 minutes") \
.groupBy(
session_window,
events.userId) \
.count()import spark.implicits._
val events = ... // streaming DataFrame of schema { timestamp: Timestamp, userId: String }
val sessionWindow = session_window($"timestamp", when($"userId" === "user1", "5 seconds")
.when($"userId" === "user2", "20 seconds")
.otherwise("5 minutes"))
// Group the data by session window and userId, and compute the count of each group
val sessionizedCounts = events
.withWatermark("timestamp", "10 minutes")
.groupBy(
Column(sessionWindow),
$"userId")
.count()Dataset<Row> events = ... // streaming DataFrame of schema { timestamp: Timestamp, userId: String }
SessionWindow sessionWindow = session_window(col("timestamp"), when(col("userId").equalTo("user1"), "5 seconds")
.when(col("userId").equalTo("user2"), "20 seconds")
.otherwise("5 minutes"))
// Group the data by session window and userId, and compute the count of each group
Dataset<Row> sessionizedCounts = events
.withWatermark("timestamp", "10 minutes")
.groupBy(
new Column(sessionWindow),
col("userId"))
.count();ストリーミングクエリでセッションウィンドウを使用する場合、次のような制限があることに注意してください。
- 「Update mode」は出力モードとしてサポートされていません。
- グループ化キーに
session_window以外に少なくとも 1 つの列が必要です。
バッチクエリの場合、グローバルウィンドウ (グループ化キーに session_window のみがある) がサポートされています。
デフォルトでは、Spark はセッションウィンドウ集計の部分的な集計を実行しません。これは、グループ化の前にローカルパーティションでの追加のソートが必要になるためです。これは、各ローカルパーティションで同じグループキーの入力行が少ない場合に最適ですが、ローカルパーティションに同じグループキーを持つ多数の入力行がある場合は、部分的な集計を実行してもパフォーマンスが大幅に向上する可能性があります。
spark.sql.streaming.sessionWindow.merge.sessions.in.local.partition を有効にすると、Spark が部分的な集計を実行するように指示できます。
時間ウィンドウの時間の表現
一部のユースケースでは、時間ウィンドウ化されたデータにタイムスタンプを必要とする操作を適用するために、時間ウィンドウの時間の表現を抽出する必要があります。1 つの例は、連鎖した時間ウィンドウ集計です。ここでは、ユーザーは 1 時間のタンブリング時間ウィンドウに対して 5 分の時間ウィンドウを定義したいと考えています。たとえば、1 時間のタンブリング時間ウィンドウに対して 5 分の時間ウィンドウを定義したいとします。
これを達成するには、次の 2 つの方法があります。
- 時間ウィンドウ列をパラメータとして
window_timeSQL 関数を使用する - 時間ウィンドウ列をパラメータとして
windowSQL 関数を使用する
window_time 関数は、時間ウィンドウの時間を表すタイムスタンプを生成します。結果を window 関数のパラメータ (またはタイムスタンプを必要とする場所) に渡して、タイムスタンプを必要とする時間ウィンドウでの操作を実行できます。
words = ... # streaming DataFrame of schema { timestamp: Timestamp, word: String }
# Group the data by window and word and compute the count of each group
windowedCounts = words.groupBy(
window(words.timestamp, "10 minutes", "5 minutes"),
words.word
).count()
# Group the windowed data by another window and word and compute the count of each group
anotherWindowedCounts = windowedCounts.groupBy(
window(window_time(windowedCounts.window), "1 hour"),
windowedCounts.word
).count()import spark.implicits._
val words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String }
// Group the data by window and word and compute the count of each group
val windowedCounts = words.groupBy(
window($"timestamp", "10 minutes", "5 minutes"),
$"word"
).count()
// Group the windowed data by another window and word and compute the count of each group
val anotherWindowedCounts = windowedCounts.groupBy(
window(window_time($"window"), "1 hour"),
$"word"
).count()Dataset<Row> words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String }
// Group the data by window and word and compute the count of each group
Dataset<Row> windowedCounts = words.groupBy(
functions.window(words.col("timestamp"), "10 minutes", "5 minutes"),
words.col("word")
).count();
// Group the windowed data by another window and word and compute the count of each group
Dataset<Row> anotherWindowedCounts = windowedCounts.groupBy(
functions.window(functions.window_time("window"), "1 hour"),
windowedCounts.col("word")
).count();window 関数は、タイムスタンプ列だけでなく、時間ウィンドウ列も受け取ります。これは、ユーザーが連鎖した時間ウィンドウ集計を適用したい場合に特に役立ちます。
words = ... # streaming DataFrame of schema { timestamp: Timestamp, word: String }
# Group the data by window and word and compute the count of each group
windowedCounts = words.groupBy(
window(words.timestamp, "10 minutes", "5 minutes"),
words.word
).count()
# Group the windowed data by another window and word and compute the count of each group
anotherWindowedCounts = windowedCounts.groupBy(
window(windowedCounts.window, "1 hour"),
windowedCounts.word
).count()import spark.implicits._
val words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String }
// Group the data by window and word and compute the count of each group
val windowedCounts = words.groupBy(
window($"timestamp", "10 minutes", "5 minutes"),
$"word"
).count()
// Group the windowed data by another window and word and compute the count of each group
val anotherWindowedCounts = windowedCounts.groupBy(
window($"window", "1 hour"),
$"word"
).count()Dataset<Row> words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String }
// Group the data by window and word and compute the count of each group
Dataset<Row> windowedCounts = words.groupBy(
functions.window(words.col("timestamp"), "10 minutes", "5 minutes"),
words.col("word")
).count();
// Group the windowed data by another window and word and compute the count of each group
Dataset<Row> anotherWindowedCounts = windowedCounts.groupBy(
functions.window("window", "1 hour"),
windowedCounts.col("word")
).count();ウォーターマーキングが集計状態をクリーンアップするための条件
集計クエリでウォーターマーキングが集計状態をクリーンアップするには、次の条件を満たす必要があることに注意してください (Spark 2.1.1 時点、将来変更される可能性があります)。
-
出力モードは Append または Update である必要があります。 Complete モードは、すべての集計データを保持する必要があるため、ウォーターマーキングを使用して中間状態を破棄することはできません。各出力モードのセマンティクスに関する詳細については、「出力モード」セクションを参照してください。
-
集計には、イベントタイム列、またはイベントタイム列の
windowが必要です。 -
withWatermarkは、集計列とは異なる列でウォーターマークが定義されている場合、Append 出力モードでは無効です。たとえば、df.withWatermark("time", "1 min").groupBy("time2").count()は無効です。 -
withWatermarkは、ウォーターマークの詳細が使用されるように、集計の前に呼び出す必要があります。たとえば、Append 出力モードではdf.groupBy("time").count().withWatermark("time", "1 min")は無効です。
ウォーターマーキングによる集計のセマンティック保証
-
「2 時間」のウォーターマーク遅延 (
withWatermarkで設定) は、エンジンが 2 時間未満遅延したデータを決して破棄しないことを保証します。つまり、それまでに処理された最新データよりも 2 時間未満遅延したデータは、必ず集計されることが保証されます。 -
ただし、保証は一方通行のみです。2 時間以上遅延したデータは破棄されるとは限りません。破棄される可能性もあれば、集計される可能性もあります。データが遅延するほど、エンジンが処理する可能性は低くなります。
結合操作
構造化ストリーミングは、ストリーミング Dataset/DataFrame を静的 Dataset/DataFrame と、あるいは別のストリーミング Dataset/DataFrame と結合することをサポートしています。ストリーミング結合の結果は、前のセクションのストリーミング集計の結果と同様に、増分的に生成されます。このセクションでは、上記のケースでサポートされている結合の種類 (内部結合、外部結合など) を調べます。サポートされているすべての結合タイプにおいて、ストリーミング Dataset/DataFrame との結合結果は、ストリームに含まれるデータと同じデータを持つ静的 Dataset/DataFrame との結合結果とまったく同じになります。
ストリーム-静的結合
Spark 2.0 の導入以来、構造化ストリーミングは、ストリーミング DataFrame/Dataset と静的 DataFrame/Dataset との結合 (内部結合および一部の外部結合) をサポートしてきました。簡単な例を以下に示します。
staticDf = spark.read. ...
streamingDf = spark.readStream. ...
streamingDf.join(staticDf, "type") # inner equi-join with a static DF
streamingDf.join(staticDf, "type", "left_outer") # left outer join with a static DFval staticDf = spark.read. ...
val streamingDf = spark.readStream. ...
streamingDf.join(staticDf, "type") // inner equi-join with a static DF
streamingDf.join(staticDf, "type", "left_outer") // left outer join with a static DFDataset<Row> staticDf = spark.read(). ...;
Dataset<Row> streamingDf = spark.readStream(). ...;
streamingDf.join(staticDf, "type"); // inner equi-join with a static DF
streamingDf.join(staticDf, "type", "left_outer"); // left outer join with a static DFstaticDf <- read.df(...)
streamingDf <- read.stream(...)
joined <- merge(streamingDf, staticDf, sort = FALSE) # inner equi-join with a static DF
joined <- join(
streamingDf,
staticDf,
streamingDf$value == staticDf$value,
"left_outer") # left outer join with a static DFストリーム-静的結合はステートフルではないため、状態管理は必要ありません。ただし、一部の種類のストリーム-静的外部結合はまだサポートされていません。これらは、この結合セクションの 末尾 にリストされています。
ストリーム-ストリーム結合
Spark 2.3 では、ストリーム-ストリーム結合のサポートが追加されました。つまり、2 つのストリーミング Dataset/DataFrame を結合できます。2 つのデータストリーム間の結合結果を生成する課題は、任意の時点で、両方の結合側のデータセットのビューが不完全であるため、入力間の一致を見つけることがはるかに困難になることです。1 つの入力ストリームから受信した各行は、もう一方の入力ストリームからまだ受信されていない将来の行と一致する可能性があります。したがって、両方の入力ストリームについて、過去の入力をストリーミング状態としてバッファリングするため、将来の各入力と過去の入力を一致させ、それに応じて結合された結果を生成できます。さらに、ストリーミング集計と同様に、遅延した順序外のデータを自動的に処理し、ウォーターマークを使用して状態を制限できます。サポートされているさまざまな種類のストリーム-ストリーム結合とその使用方法について説明します。
オプションのウォーターマーキングによる内部結合
任意の種類の列と任意の種類の結合条件による内部結合がサポートされています。ただし、ストリームが実行されると、すべての過去の入力が保存される必要があるため、ストリーミング状態のサイズは無限に増加し続けます。無限の状態を回避するために、無限に古い入力が将来の一致しないようにし、したがって状態からクリアできるように、追加の結合条件を定義する必要があります。つまり、結合で次の追加手順を実行する必要があります。
-
両方の入力でウォーターマーク遅延を定義して、エンジンの入力がどれだけ遅延しているかを把握できるようにします (ストリーミング集計と同様)。
-
2 つの入力間でイベントタイムの制約を定義して、エンジンが一方の入力の古い行がもう一方の入力との一致に必要なくなる (つまり、時間制約を満たさなくなる) 時期を把握できるようにします。この制約は、次の 2 つの方法のいずれかで定義できます。
-
時間範囲結合条件 (例:
...JOIN ON leftTime BETWEEN rightTime AND rightTime + INTERVAL 1 HOUR)、 -
イベントタイムウィンドウでの結合 (例:
...JOIN ON leftTimeWindow = rightTimeWindow)。
-
例で理解しましょう。
たとえば、広告インプレッション (広告が表示されたとき) のストリームを、広告のユーザークリックの別のストリームと結合して、インプレッションが収益化可能なクリックにつながった時期を相関させたいとします。このストリーム-ストリーム結合での状態クリーンアップを許可するには、ウォーターマーク遅延と時間制約を次のように指定する必要があります。
-
ウォーターマーク遅延: インプレッションとその対応するクリックは、イベントタイムでそれぞれ最大 2 時間と 3 時間遅延/順序外になる可能性があるとします。
-
イベントタイム範囲条件: クリックは、対応するインプレッションの 0 秒から 1 時間の範囲内で発生する可能性があるとします。
コードは次のようになります。
from pyspark.sql.functions import expr
impressions = spark.readStream. ...
clicks = spark.readStream. ...
# Apply watermarks on event-time columns
impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours")
clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours")
# Join with event-time constraints
impressionsWithWatermark.join(
clicksWithWatermark,
expr("""
clickAdId = impressionAdId AND
clickTime >= impressionTime AND
clickTime <= impressionTime + interval 1 hour
""")
)import org.apache.spark.sql.functions.expr
val impressions = spark.readStream. ...
val clicks = spark.readStream. ...
// Apply watermarks on event-time columns
val impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours")
val clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours")
// Join with event-time constraints
impressionsWithWatermark.join(
clicksWithWatermark,
expr("""
clickAdId = impressionAdId AND
clickTime >= impressionTime AND
clickTime <= impressionTime + interval 1 hour
""")
)import static org.apache.spark.sql.functions.expr
Dataset<Row> impressions = spark.readStream(). ...
Dataset<Row> clicks = spark.readStream(). ...
// Apply watermarks on event-time columns
Dataset<Row> impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours");
Dataset<Row> clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours");
// Join with event-time constraints
impressionsWithWatermark.join(
clicksWithWatermark,
expr(
"clickAdId = impressionAdId AND " +
"clickTime >= impressionTime AND " +
"clickTime <= impressionTime + interval 1 hour ")
);impressions <- read.stream(...)
clicks <- read.stream(...)
# Apply watermarks on event-time columns
impressionsWithWatermark <- withWatermark(impressions, "impressionTime", "2 hours")
clicksWithWatermark <- withWatermark(clicks, "clickTime", "3 hours")
# Join with event-time constraints
joined <- join(
impressionsWithWatermark,
clicksWithWatermark,
expr(
paste(
"clickAdId = impressionAdId AND",
"clickTime >= impressionTime AND",
"clickTime <= impressionTime + interval 1 hour"
)))ストリーム-ストリーム内部結合のウォーターマーキングによるセマンティック保証
これは、集計のウォーターマーキングによって提供される保証 と似ています。2 時間のウォーターマーク遅延は、エンジンが 2 時間未満遅延したデータを決して破棄しないことを保証します。ただし、2 時間以上遅延したデータは処理されるとは限りません。
ウォーターマーキングによる外部結合
内部結合ではウォーターマーク + イベントタイム制約はオプションですが、外部結合では指定する必要があります。これは、外部結合の NULL 結果を生成するために、エンジンがいずれかの入力行が将来一致しないことを知る必要があるためです。したがって、正しい結果を生成するには、ウォーターマーク + イベントタイム制約を指定する必要があります。したがって、外部結合を持つクエリは、外部結合であることを指定する追加のパラメータがあることを除けば、前の広告収益化の例と非常によく似ています。
impressionsWithWatermark.join(
clicksWithWatermark,
expr("""
clickAdId = impressionAdId AND
clickTime >= impressionTime AND
clickTime <= impressionTime + interval 1 hour
"""),
"leftOuter" # can be "inner", "leftOuter", "rightOuter", "fullOuter", "leftSemi"
)impressionsWithWatermark.join(
clicksWithWatermark,
expr("""
clickAdId = impressionAdId AND
clickTime >= impressionTime AND
clickTime <= impressionTime + interval 1 hour
"""),
joinType = "leftOuter" // can be "inner", "leftOuter", "rightOuter", "fullOuter", "leftSemi"
)impressionsWithWatermark.join(
clicksWithWatermark,
expr(
"clickAdId = impressionAdId AND " +
"clickTime >= impressionTime AND " +
"clickTime <= impressionTime + interval 1 hour "),
"leftOuter" // can be "inner", "leftOuter", "rightOuter", "fullOuter", "leftSemi"
);joined <- join(
impressionsWithWatermark,
clicksWithWatermark,
expr(
paste(
"clickAdId = impressionAdId AND",
"clickTime >= impressionTime AND",
"clickTime <= impressionTime + interval 1 hour"),
"left_outer" # can be "inner", "left_outer", "right_outer", "full_outer", "left_semi"
))ストリーム-ストリーム外部結合のウォーターマーキングによるセマンティック保証
外部結合は、内部結合 と同じ保証を、ウォーターマーク遅延とデータが破棄されるかどうかに関して持ちます。
注意点
外部結果の生成方法に関して、留意すべき重要な特性がいくつかあります。
-
外部 NULL 結果は、指定されたウォーターマーク遅延と時間範囲条件に依存する遅延で生成されます。 これは、一致がなく、将来一致しなくなることを保証するために、エンジンがその時間待つ必要があるためです。
-
マイクロバッチエンジンの現在の実装では、ウォーターマークはマイクロバッチの終わりに進み、次のマイクロバッチは更新されたウォーターマークを使用して状態をクリーンアップし、外部結果を出力します。処理される新しいデータがある場合にのみマイクロバッチをトリガーするため、ストリームがしばらくデータを受信しない場合、外部 (左または右の両方) の出力が遅延する可能性があります。要するに、結合されている 2 つの入力ストリームのいずれかがしばらくデータを受信しない場合、外部 (左または右) の出力が遅延する可能性があります。
ウォーターマーキングによる半結合
半結合は、右側と一致する左側の関係からの値を返します。左半結合とも呼ばれます。外部結合と同様に、半結合にはウォーターマーク + イベントタイム制約を指定する必要があります。これは、左側の不一致の入力行をエビクトするため、エンジンが左側の入力行が将来右側のいずれとも一致しないことを知る必要があるためです。
ストリーム-ストリーム半結合のウォーターマーキングによるセマンティック保証
半結合は、内部結合 と同じ保証を、ウォーターマーク遅延とデータが破棄されるかどうかに関して持ちます。
ストリーミングクエリでの結合のサポートマトリックス
| 左入力 | 右入力 | 結合タイプ | |
|---|---|---|---|
| 静的 | 静的 | すべて | サポートされています。ストリーミングデータではなく、ストリーミングクエリに存在する場合でも |
| ストリーム | 静的 | 内部 | サポートされています。ステートフルではありません |
| 左外部 | サポートされています。ステートフルではありません | ||
| 右外部 | サポートされていません | ||
| 完全外部 | サポートされていません | ||
| 左半 | サポートされています。ステートフルではありません | ||
| 静的 | ストリーム | 内部 | サポートされています。ステートフルではありません |
| 左外部 | サポートされていません | ||
| 右外部 | サポートされています。ステートフルではありません | ||
| 完全外部 | サポートされていません | ||
| 左半 | サポートされていません | ||
| ストリーム | ストリーム | 内部 | サポートされています。両側でオプションでウォーターマークを指定 + 状態クリーンアップのための時間制約 |
| 左外部 | 条件付きでサポートされています。正しい結果を得るために右側でウォーターマークを指定する必要があります + 時間制約。すべての状態クリーンアップのために左側でオプションでウォーターマークを指定できます。 | ||
| 右外部 | 条件付きでサポートされています。正しい結果を得るために左側でウォーターマークを指定する必要があります + 時間制約。すべての状態クリーンアップのために右側でオプションでウォーターマークを指定できます。 | ||
| 完全外部 | 条件付きでサポートされています。正しい結果を得るために一方の側でウォーターマークを指定する必要があります + 時間制約。すべての状態クリーンアップのために他方の側でオプションでウォーターマークを指定できます。 | ||
| 左半 | 条件付きでサポートされています。正しい結果を得るために右側でウォーターマークを指定する必要があります + 時間制約。すべての状態クリーンアップのために左側でオプションでウォーターマークを指定できます。 | ||
サポートされる結合の詳細
-
結合は連鎖させることができます。つまり、
df1.join(df2, ...).join(df3, ...).join(df4, ....)を実行できます。 -
Spark 2.4 以降では、クエリが Append 出力モードの場合にのみ結合を使用できます。その他の出力モードはまだサポートされていません。
-
mapGroupsWithState および flatMapGroupsWithState を結合の前後に使用することはできません。
Append 出力モードでは、結合の前後に集計、重複排除、ストリーム-ストリーム結合などの非マップライクな操作を含むクエリを構築できます。
たとえば、両方のストリームでの時間ウィンドウ集計と、イベントタイムウィンドウを使用したストリーム-ストリーム結合の例を以下に示します。
clicksWindow = clicksWithWatermark.groupBy(
clicksWithWatermark.clickAdId,
window(clicksWithWatermark.clickTime, "1 hour")
).count()
impressionsWindow = impressionsWithWatermark.groupBy(
impressionsWithWatermark.impressionAdId,
window(impressionsWithWatermark.impressionTime, "1 hour")
).count()
clicksWindow.join(impressionsWindow, "window", "inner")val clicksWindow = clicksWithWatermark
.groupBy(window("clickTime", "1 hour"))
.count()
val impressionsWindow = impressionsWithWatermark
.groupBy(window("impressionTime", "1 hour"))
.count()
clicksWindow.join(impressionsWindow, "window", "inner")Dataset<Row> clicksWindow = clicksWithWatermark
.groupBy(functions.window(clicksWithWatermark.col("clickTime"), "1 hour"))
.count();
Dataset<Row> impressionsWindow = impressionsWithWatermark
.groupBy(functions.window(impressionsWithWatermark.col("impressionTime"), "1 hour"))
.count();
clicksWindow.join(impressionsWindow, "window", "inner");時間範囲結合条件を使用したストリーム-ストリーム結合と、その後の時間ウィンドウ集計の例を以下に示します。
joined = impressionsWithWatermark.join(
clicksWithWatermark,
expr("""
clickAdId = impressionAdId AND
clickTime >= impressionTime AND
clickTime <= impressionTime + interval 1 hour
"""),
"leftOuter" # can be "inner", "leftOuter", "rightOuter", "fullOuter", "leftSemi"
)
joined.groupBy(
joined.clickAdId,
window(joined.clickTime, "1 hour")
).count()val joined = impressionsWithWatermark.join(
clicksWithWatermark,
expr("""
clickAdId = impressionAdId AND
clickTime >= impressionTime AND
clickTime <= impressionTime + interval 1 hour
"""),
joinType = "leftOuter" // can be "inner", "leftOuter", "rightOuter", "fullOuter", "leftSemi"
)
joined
.groupBy($"clickAdId", window($"clickTime", "1 hour"))
.count()Dataset<Row> joined = impressionsWithWatermark.join(
clicksWithWatermark,
expr(
"clickAdId = impressionAdId AND " +
"clickTime >= impressionTime AND " +
"clickTime <= impressionTime + interval 1 hour "),
"leftOuter" // can be "inner", "leftOuter", "rightOuter", "fullOuter", "leftSemi"
);
joined
.groupBy(joined.col("clickAdId"), functions.window(joined.col("clickTime"), "1 hour"))
.count();ストリーミング重複排除
イベント内のユニークな識別子を使用して、データストリーム内のレコードの重複を排除できます。これは、ユニークな識別子列での静的な重複排除とまったく同じです。クエリは、重複レコードをフィルタリングできるように、以前のレコードから必要な量のデータを格納します。集計と同様に、ウォーターマーキングの有無にかかわらず重複排除を使用できます。
-
ウォーターマークあり - 重複レコードが到着する可能性のある遅延の上限がある場合、イベントタイム列にウォーターマークを定義し、GUID とイベントタイム列の両方を使用して重複を排除できます。クエリは、ウォーターマークを使用して、重複が予想されなくなった過去のレコードから古い状態データを削除します。これにより、クエリが維持する必要がある状態の量が制限されます。
-
ウォーターマークなし - 重複レコードが到着する時期に制限がないため、クエリはすべての過去のレコードのデータを状態として格納します。
streamingDf = spark.readStream. ...
# Without watermark using guid column
streamingDf.dropDuplicates(["guid"])
# With watermark using guid and eventTime columns
streamingDf \
.withWatermark("eventTime", "10 seconds") \
.dropDuplicates(["guid", "eventTime"])val streamingDf = spark.readStream. ... // columns: guid, eventTime, ...
// Without watermark using guid column
streamingDf.dropDuplicates("guid")
// With watermark using guid and eventTime columns
streamingDf
.withWatermark("eventTime", "10 seconds")
.dropDuplicates("guid", "eventTime")Dataset<Row> streamingDf = spark.readStream(). ...; // columns: guid, eventTime, ...
// Without watermark using guid column
streamingDf.dropDuplicates("guid");
// With watermark using guid and eventTime columns
streamingDf
.withWatermark("eventTime", "10 seconds")
.dropDuplicates("guid", "eventTime");streamingDf <- read.stream(...)
# Without watermark using guid column
streamingDf <- dropDuplicates(streamingDf, "guid")
# With watermark using guid and eventTime columns
streamingDf <- withWatermark(streamingDf, "eventTime", "10 seconds")
streamingDf <- dropDuplicates(streamingDf, "guid", "eventTime")特にストリーミングの場合、ウォーターマークのタイム範囲内で、イベント内のユニークな識別子を使用してデータストリーム内のレコードの重複を排除できます。たとえば、ウォーターマークの遅延しきい値を「1 時間」に設定した場合、1 時間以内に発生した重複イベントは正しく重複排除されます。(詳細については、dropDuplicatesWithinWatermark の API ドキュメントを参照してください。)
これは、イベントタイム列がユニークな識別子の一部にできないユースケースに対処するために使用できます。これは、イベントタイムが同じレコードで異なる場合が多いためです。(例: イベントタイムが書き込み時に発生する、べき等でないライター)
ユーザーは、重複イベント間の最大タイムスタンプ差よりも長いウォーターマークの遅延しきい値を設定することをお勧めします。
この機能は、ストリーミング DataFrame/Dataset にウォーターマークと遅延しきい値を設定する必要があります。
streamingDf = spark.readStream. ...
# deduplicate using guid column with watermark based on eventTime column
streamingDf \
.withWatermark("eventTime", "10 hours") \
.dropDuplicatesWithinWatermark(["guid"])val streamingDf = spark.readStream. ... // columns: guid, eventTime, ...
// deduplicate using guid column with watermark based on eventTime column
streamingDf
.withWatermark("eventTime", "10 hours")
.dropDuplicatesWithinWatermark("guid")Dataset<Row> streamingDf = spark.readStream(). ...; // columns: guid, eventTime, ...
// deduplicate using guid column with watermark based on eventTime column
streamingDf
.withWatermark("eventTime", "10 hours")
.dropDuplicatesWithinWatermark("guid");複数のウォーターマークを処理するためのポリシー
ストリーミングクエリは、和集合または結合された複数の入力ストリームを持つことができます。各入力ストリームは、ステートフルな操作に対して許容する必要のある遅延データに対して異なるしきい値を持つことができます。これらのしきい値は、各入力ストリームで withWatermarks("eventTime", delay) を使用して指定します。たとえば、inputStream1 と inputStream2 の間のストリーム-ストリーム結合を持つクエリを考えてみましょう。
inputStream1.withWatermark("eventTime1", "1 hour")
.join(
inputStream2.withWatermark("eventTime2", "2 hours"),
joinCondition)クエリを実行中、構造化ストリーミングは、各入力ストリームで検出された最大イベントタイムを個別に追跡し、対応する遅延に基づいてウォーターマークを計算し、ステートフルな操作に使用する単一のグローバルウォーターマークを選択します。デフォルトでは、いずれかのストリームが他のストリームに遅れをとった場合 (たとえば、上流の障害のためにいずれかのストリームがデータの受信を停止した場合) にデータが誤って遅すぎるとして破棄されないように、最小値がグローバルウォーターマークとして選択されます。つまり、グローバルウォーターマークは最も遅いストリームのペースで安全に移動し、クエリ出力はそれに応じて遅延します。
ただし、場合によっては、遅いストリームからのデータの破棄を意味しても、より高速な結果を得たい場合があります。Spark 2.4 以降では、複数のウォーターマークポリシーを設定して、SQL 設定 spark.sql.streaming.multipleWatermarkPolicy を max (デフォルトは min) に設定することで、最大値をグローバルウォーターマークとして選択できます。これにより、グローバルウォーターマークは最も速いストリームのペースで移動します。ただし、副作用として、遅いストリームからのデータが積極的に破棄されます。したがって、この設定は慎重に使用してください。
任意のステートフル操作
多くのユースケースでは、集計よりも高度なステートフルな操作が必要です。たとえば、多くのユースケースでは、イベントのデータストリームからセッションを追跡する必要があります。このようなセッション化を行うには、任意の種類のデータを状態として保存し、各トリガーでデータストリームイベントを使用して状態に対して任意の操作を実行する必要があります。
Spark 2.2 以降、レガシーな mapGroupsWithState および flatMapGroupsWithState 演算子を使用してこれを行うことができます。どちらの演算子も、グループ化された Dataset にユーザー定義コードを適用して、ユーザー定義状態を更新できます。さらに具体的な詳細については、API ドキュメント (Scala/Java) および例 (Scala/Java) を参照してください。
Spark 4.0 リリース以降、ユーザーは新しい transformWithState 演算子を使用して複雑なステートフルアプリケーションを構築することが推奨されます。詳細については、こちらの 詳細なドキュメントを参照してください。
Spark はチェックおよび強制できませんが、状態関数は出力モードのセマンティクスに関して実装する必要があります。たとえば、Update モードでは、Spark は状態関数が現在のウォーターマークプラス許可される遅延レコード遅延よりも古い行を発行することを期待していませんが、Append モードでは状態関数はこれらの行を発行できます。
サポートされていない操作
ストリーミング DataFrame/Dataset でサポートされていない DataFrame/Dataset 操作がいくつかあります。その一部を以下に示します。
-
ストリーミング Dataset での Limit および最初の N 行の取得はサポートされていません。
-
ストリーミング Dataset での Distinct 操作はサポートされていません。
-
ストリーミング Dataset でのソート操作は、集計後かつ Complete Output Mode の場合にのみサポートされます。
-
ストリーミング Dataset でのいくつかの種類の外部結合はサポートされていません。詳細については、結合操作セクションの サポートマトリックス を参照してください。
-
Update および Complete モードでは、ストリーミング Dataset で複数のステートフルな操作を連鎖させることはサポートされていません。
- Append モードでは、mapGroupsWithState/flatMapGroupsWithState 操作の後に別のステートフルな操作を行うことはサポートされていません。
- 既知の回避策は、ストリーミングクエリを、各クエリに 1 つのステートフルな操作を持つ複数のクエリに分割し、クエリごとにエンドツーエンドで正確に 1 回実行することを保証することです。最後のクエリのエンドツーエンドで正確に 1 回実行することはオプションです。
さらに、ストリーミング Dataset では機能しない Dataset メソッドがいくつかあります。これらは、クエリをすぐに実行して結果を返すアクションですが、ストリーミング Dataset では意味がありません。むしろ、これらの機能は、ストリーミングクエリを明示的に開始することによって実行できます (次のセクションを参照)。
-
count()- ストリーミング Dataset から単一のカウントを返すことはできません。代わりに、ds.groupBy().count()を使用します。これは、実行中のカウントを含むストリーミング Dataset を返します。 -
foreach()- 代わりにds.writeStream.foreach(...)を使用します (次のセクションを参照)。 -
show()- 代わりにコンソールシンクを使用します (次のセクションを参照)。
これらの操作のいずれかを試みると、「operation XYZ is not supported with streaming DataFrames/Datasets」のような AnalysisException が表示されます。将来の Spark リリースでサポートされるものもありますが、ストリーミングデータで効率的に実装するのが根本的に難しいものもあります。たとえば、入力ストリームでのソートはサポートされていません。これは、ストリームで受信されたすべてのデータを追跡する必要があるためです。したがって、効率的な実行は根本的に困難です。
ステートストア
ステートストアは、読み書き操作の両方を提供するバージョン化されたキーバリューストアです。構造化ストリーミングでは、ステートストアプロバイダーを使用して、バッチ間のステートフルな操作を処理します。2 つの組み込みステートストアプロバイダー実装があります。エンドユーザーは、StateStoreProvider インターフェースを拡張することによって、独自のステートストアプロバイダーを実装することもできます。
HDFS ステートストアプロバイダー
HDFS バックエンドステートストアプロバイダーは、[[StateStoreProvider]] および [[StateStore]] のデフォルト実装です。すべてのデータは最初のステージでメモリマップに格納され、その後 HDFS 互換ファイルシステムにバックアップされます。ストアへのすべての更新はトランザクションセットで行う必要があり、各更新セットはストアのバージョンをインクリメントします。これらのバージョンは、ストアの正しいバージョンで更新を再実行するため (RDD 操作での再試行)、ストアバージョンを再生成するために使用できます。
RocksDB ステートストア実装
Spark 3.2 以降、新しい組み込みステートストア実装である RocksDB ステートストアプロバイダーが追加されました。
ストリーミングクエリにステートフルな操作 (例: ストリーミング集計、ストリーミング重複排除、ストリーム-ストリーム結合、mapGroupsWithState、flatMapGroupsWithState) があり、数百万のキーを状態として維持したい場合、マイクロバッチ処理時間に大きなばらつきを引き起こす大規模な JVM ガベージコレクション (GC) 一時停止に関連する問題に直面する可能性があります。これは、HDFSBackedStateStore の実装により、状態データがエグゼキュータの JVM メモリに格納され、大量の状態オブジェクトが JVM にメモリ圧力をかけるため、GC 一時停止が長くなることが原因です。
このような場合、RocksDB に基づいたより最適化された状態管理ソリューションを使用することを選択できます。このソリューションは、状態を JVM メモリに保持するのではなく、RocksDB を使用してネイティブメモリとローカルディスクの状態を効率的に管理します。さらに、この状態への変更は、Spark によって提供されたチェックポイントの場所に自動的に保存されるため、完全な耐障害性保証 (デフォルトの状態管理と同じ) が提供されます。
新しい組み込みステートストア実装を有効にするには、spark.sql.streaming.stateStore.providerClass を org.apache.spark.sql.execution.streaming.state.RocksDBStateStoreProvider に設定します。
RocksDB インスタンスのステートストアプロバイダーに関連する設定を以下に示します。
| 設定名 | 説明 | デフォルト値 |
|---|---|---|
| spark.sql.streaming.stateStore.rocksdb.compactOnCommit | コミット操作のために RocksDB インスタンスの範囲コンパクションを実行するかどうか | False |
| spark.sql.streaming.stateStore.rocksdb.changelogCheckpointing.enabled | RocksDB StateStore コミット中にスナップショットではなく変更ログをアップロードするかどうか | False |
| spark.sql.streaming.stateStore.rocksdb.blockSizeKB | RocksDB のデフォルトの SST ファイル形式である BlockBasedTable の RocksDB のブロックごとにパックされたユーザーデータの約 KB サイズ。 | 4 |
| spark.sql.streaming.stateStore.rocksdb.blockCacheSizeMB | ブロックキャッシュのサイズ容量 (MB)。 | 8 |
| spark.sql.streaming.stateStore.rocksdb.lockAcquireTimeoutMs | RocksDB インスタンスのロード操作でロックを取得するための待機時間 (ミリ秒)。 | 60000 |
| spark.sql.streaming.stateStore.rocksdb.maxOpenFiles | RocksDB インスタンスで使用できる開いているファイルの数。値 -1 は、開いているファイルが常に開いたままになることを意味します。開いているファイル制限に達した場合、RocksDB は開いているファイルキャッシュからエントリをエビクトし、それらのファイルディスクリプタを閉じ、キャッシュからエントリを削除します。 | -1 |
| spark.sql.streaming.stateStore.rocksdb.resetStatsOnLoad | ロード時に RocksDB のすべてのティッカーとヒストグラム統計をリセットするかどうか。 | True |
| spark.sql.streaming.stateStore.rocksdb.trackTotalNumberOfRows | 状態ストアの合計行数を追跡するかどうか。「パフォーマンスに関する考慮事項」の詳細を参照してください。 | True |
| spark.sql.streaming.stateStore.rocksdb.writeBufferSizeMB | RocksDB の MemTable の最大サイズ。値 -1 は、RocksDB 内部のデフォルト値が使用されることを意味します。 | -1 |
| spark.sql.streaming.stateStore.rocksdb.maxWriteBufferNumber | RocksDB の MemTable の最大数。アクティブと不活性の両方。値 -1 は、RocksDB 内部のデフォルト値が使用されることを意味します。 | -1 |
| spark.sql.streaming.stateStore.rocksdb.boundedMemoryUsage | 単一ノードの RocksDB ステートストアインスタンスの合計メモリ使用量が制限されているかどうか。 | false |
| spark.sql.streaming.stateStore.rocksdb.maxMemoryUsageMB | 単一ノードの RocksDB ステートストアインスタンスの合計メモリ制限 (MB)。 | 500 |
| spark.sql.streaming.stateStore.rocksdb.writeBufferCacheRatio | maxMemoryUsageMB を使用して、単一ノードのすべての RocksDB インスタンスに割り当てられたメモリのうち、書き込みバッファが占める合計メモリの割合。 | 0.5 |
| spark.sql.streaming.stateStore.rocksdb.highPriorityPoolRatio | maxMemoryUsageMB を使用して、単一ノードのすべての RocksDB インスタンスに割り当てられたメモリのうち、高優先度プール内のブロックが占める合計メモリの割合。 | 0.1 |
| spark.sql.streaming.stateStore.rocksdb.allowFAllocate | RocksDB ランタイムがフォールアロケーションを使用してログなどのディスクスペースを事前割り当てすることを許可します。書き込みパフォーマンスと引き換えに、多数の小さなステートストアを持つアプリの場合は無効にします。 | true |
| spark.sql.streaming.stateStore.rocksdb.compression | RocksDB で使用される圧縮タイプ。文字列は、RocksDB Java API getCompressionType() を介して RocksDB 圧縮タイプに変換されます。 | lz4 |
RocksDB ステートストアのメモリ管理
RocksDB は、memtables、ブロックキャッシュ、フィルター/インデックスブロックなどのさまざまなオブジェクトにメモリを割り当てます。制限がない場合、複数のインスタンスにわたる RocksDB のメモリ使用量は無限に増加し、OOM (メモリ不足) の問題を引き起こす可能性があります。RocksDB は、書き込みバッファマネージャー機能を使用して、単一ノードのすべての DB インスタンスのメモリ使用量を制限する方法を提供します。Spark 構造化ストリーミングデプロイメントで RocksDB のメモリ使用量を制限したい場合は、spark.sql.streaming.stateStore.rocksdb.boundedMemoryUsage 設定を true に設定することで、この機能を有効にできます。また、spark.sql.streaming.stateStore.rocksdb.maxMemoryUsageMB の値を静的な数値またはノードで利用可能な物理メモリの割合として設定することで、RocksDB インスタンスの最大許容メモリを決定できます。個々の RocksDB インスタンスの制限は、spark.sql.streaming.stateStore.rocksdb.writeBufferSizeMB および spark.sql.streaming.stateStore.rocksdb.maxWriteBufferNumber を必要な値に設定することでも構成できます。デフォルトでは、RocksDB の内部デフォルトがこれらの設定に使用されます。
boundedMemoryUsage 設定は、RocksDB の合計メモリ使用量にソフトリミットを有効にすることに注意してください。したがって、高レベルリーダーに割り当てられたすべてのブロックが使用中の場合、RocksDB によって使用される合計メモリはこの値を超える可能性があります。厳密な制限を有効にすることは、クエリの失敗を引き起こすため、現時点では不可能であり、追加のノードにまたがる状態の再分散はサポートされていません。
RocksDB ステートストアの変更ログチェックポイント
Spark の新しいバージョンでは、RocksDB ステートストアの変更ログチェックポイントが導入されています。RocksDB ステートストアの従来のチェックポイントメカニズムは、マニフェストファイルと RocksDB インスタンスの新規生成された RocksDB SST ファイルが耐久性のあるストレージにアップロードされるインクリメンタルスナップショットチェックポイントです。変更ログチェックポイントは、RocksDB インスタンスのデータファイルをアップロードする代わりに、耐久性のために最後のチェックポイント以降の状態に加えられた変更をアップロードします。スナップショットは、予測可能な障害復旧と変更ログのトリミングのために定期的にバックグラウンドで永続化されます。変更ログチェックポイントは、RocksDB インスタンスのスナップショットをキャプチャしてアップロードするコストを回避し、ストリーミングクエリのレイテンシを大幅に削減します。
変更ログチェックポイントはデフォルトで無効になっています。 spark.sql.streaming.stateStore.rocksdb.changelogCheckpointing.enabled 設定を true に設定することで、RocksDB ステートストアの変更ログチェックポイントを有効にできます。変更ログチェックポイントは、従来のチェックポイントメカニズムと後方互換性があるように設計されています。RocksDB ステートストアプロバイダーは、両方向で 2 つのチェックポイントメカニズム間の移行をシームレスにサポートします。これにより、古い状態チェックポイントを破棄することなく、変更ログチェックポイントのパフォーマンス上の利点を活用できます。変更ログチェックポイントをサポートする Spark のバージョンでは、Spark セッションで変更ログチェックポイントを有効にすることで、古い Spark バージョンからストリーミングクエリを移行できます。逆に、新しい Spark バージョンで変更ログチェックポイントを安全に無効にすると、すでに変更ログチェックポイントで実行されているクエリは従来のチェックポイントに戻ります。チェックポイントメカニズムの変更を適用するにはストリーミングクエリを再起動する必要がありますが、そのプロセスでパフォーマンスの低下は観察されません。
パフォーマンスに関する考慮事項
- RocksDB ステートストアのパフォーマンスを向上させるために、合計行数の追跡を無効にしたい場合があります。
行数の追跡は、書き込み操作に追加のルックアップをもたらします。特に、状態演算子のメトリック値が大きい場合 (numRowsUpdated、numRowsRemoved) は、RocksDB ステートストアのチューニングで設定をオフにすることを試みることをお勧めします。
クエリを再起動中に設定を変更できます。これにより、「可観測性 vs パフォーマンス」のトレードオフの決定を変更できます。設定が無効になっている場合、状態内の行数 (numTotalStateRows) は 0 として報告されます。
ステートストアとタスクのローカリティ
ステートフルな操作は、エグゼキュータのステートストアにイベントの状態を格納します。ステートストアは、状態を格納するためにメモリやディスクスペースなどのリソースを消費します。そのため、異なるストリーミングバッチ間で同じエグゼキュータでステートストアプロバイダーを実行し続ける方が効率的です。ステートストアプロバイダーの場所を変更すると、チェックポイントされた状態のロードに余分なオーバーヘッドが発生します。チェックポイントから状態をロードするオーバーヘッドは、外部ストレージと状態のサイズによって異なります。これは、マイクロバッチ実行のレイテンシを悪化させる傾向があります。非常に大きな状態データを処理する一部のユースケースでは、チェックポイントされた状態から新しいステートストアプロバイダーをロードすることは非常に時間がかかり、非効率的になる可能性があります。
構造化ストリーミングクエリのステートフルな操作は、Spark の RDD の優先ロケーション機能を使用して、ステートストアプロバイダーを同じエグゼキュータで実行します。次のバッチで対応するステートストアプロバイダーがこのエグゼキュータに再度スケジュールされた場合、以前の状態を再利用し、チェックポイントされた状態のロード時間を節約できます。
ただし、一般的に、優先ロケーションは必須要件ではなく、Spark が優先エグゼキュータ以外のエグゼキュータにタスクをスケジュールすることも可能です。この場合、Spark はチェックポイントされた状態から新しいエグゼキュータにステートストアプロバイダーをロードします。前のバッチで実行されたステートストアプロバイダーはすぐにアンロードされません。Spark はメンテナンスタスクを実行し、エグゼキュータで非アクティブになっているステートストアプロバイダーをチェックしてアンロードします。
タスクスケジューリングに関連する Spark 設定 (例: spark.locality.wait) を変更することで、データローカルタスクを起動するまで Spark が待機する時間を構成できます。構造化ストリーミングのステートフルな操作では、バッチ間で同じエグゼキュータでステートストアプロバイダーを実行させることができます。
特に組み込み HDFS ステートストアプロバイダーの場合、ユーザーは loadedMapCacheHitCount および loadedMapCacheMissCount のようなステートストアメトリックを確認できます。理想的には、キャッシュミス数を最小限に抑えるのが最善です。これは、Spark がチェックポイントされた状態のロードに時間を浪費しないことを意味します。ユーザーは、バッチ間で異なるエグゼキュータでステートストアプロバイダーをロードしないように、Spark のローカリティ待機設定を増やすことができます。
状態データソース (実験的)
Apache Spark は、チェックポイント内のステートストアを操作する機能を提供するストリーミング状態関連のデータソースを提供します。ユーザーは、State Data Source でバッチクエリを実行して、既存のストリーミングクエリの状態を可視化できます。
Spark 4.0 時点では、このデータソースは読み取り機能のみをサポートしています。詳細については、「State Data Source Integration Guide」を参照してください。
注意: このデータソースは現在実験的なマークが付いています。ソースオプションおよび動作 (出力) は変更される可能性があります。
ストリーミングクエリの開始
最終的な結果 DataFrame/Dataset を定義したら、残っているのはストリーミング計算を開始することだけです。これを行うには、Dataset.writeStream() から返される DataStreamWriter (Python/Scala/Java ドキュメント) を使用する必要があります。このインターフェースで、次のいずれかまたは複数を指定する必要があります。
-
出力シンクの詳細: データ形式、場所など。
-
出力モード: 出力シンクに書き込まれるものを指定します。
-
クエリ名: オプションで、識別のための一意のクエリ名を指定します。
-
トリガー間隔: オプションで、トリガー間隔を指定します。指定しない場合、システムは前の処理が完了次第、新しいデータの可用性をチェックします。前の処理が完了していないためトリガー時間が missed された場合、システムはすぐに処理をトリガーします。
-
チェックポイントの場所: エンドツーエンドの耐障害性が保証される一部の出力シンクの場合、システムがすべてのチェックポイント情報を書き込む場所を指定します。これは、HDFS 互換の耐障害性ファイルシステム上のディレクトリである必要があります。チェックポイントのセマンティクスについては、次のセクションでさらに詳しく説明します。
出力モード
いくつかの種類の出力モードがあります。
-
Append モード (デフォルト) - これはデフォルトモードで、結果テーブルに last trigger 以降に追加された新しい行のみが出力シンクに出力されます。これは、結果テーブルに追加される行が変更されないクエリでのみサポートされます。したがって、このモードは、各行が 1 回だけ出力されることを保証します (耐障害性のあるシンクを想定)。たとえば、
select、where、map、flatMap、filter、joinなどのみを含むクエリは Append モードをサポートします。 -
Complete モード - トリガーごとに、結果テーブル全体がシンクに出力されます。これは集計クエリでサポートされています。
-
Update モード - (Spark 2.1.1 以降で利用可能) 前回のトリガー以降に更新された結果テーブルの行のみがシンクに出力されます。将来のリリースで詳細が追加される予定です。
ストリーミングクエリの出力モードは、クエリの種類によって異なります。互換性マトリックスを以下に示します。
| クエリの種類 | サポートされている出力モード | 注記 | |
|---|---|---|---|
| 集計を含むクエリ | ウォーターマーク付きイベントタイム集計 | Append, Update, Complete | Append モードでは、ウォーターマークを使用して古い集計状態を削除します。ただし、ウィンドウ集計の出力は、withWatermark() で指定された遅延しきい値によって遅延します。これは、モードのセマンティクスにより、行は最終化された後(つまり、ウォーターマークが交差した後)にのみ結果テーブルに追加できるためです。詳細については、「遅延データ」セクションを参照してください。Update モードでは、ウォーターマークを使用して古い集計状態を削除します。 Complete モードでは、結果テーブル内のすべてのデータを保持するため、古い集計状態は削除されません。 |
| その他の集計 | Complete, Update | ウォーターマークが定義されていないため(その他のカテゴリでのみ定義)、古い集計状態は削除されません。 Append モードはサポートされていません。集計は更新される可能性があり、このモードのセマンティクスに違反するためです。 |
|
mapGroupsWithState を使用するクエリ |
Update | mapGroupsWithState を使用するクエリでは集計は許可されません。 |
|
flatMapGroupsWithState を使用するクエリ |
Append 操作モード | Append | flatMapGroupsWithState の後では集計が許可されます。 |
| Update 操作モード | Update | flatMapGroupsWithState を使用するクエリでは集計は許可されません。 |
|
joins を使用するクエリ |
Append | Update および Complete モードはまだサポートされていません。サポートされているジョインの種類については、「Join Operations」セクションのサポートマトリックスを参照してください。 | |
| その他のクエリ | Append, Update | Complete モードはサポートされていません。結果テーブル内にすべての未集計データを保持することが現実的ではないためです。 | |
出力シンク
組み込みの出力シンクにはいくつかの種類があります。
- File sink - 出力をディレクトリに保存します。
writeStream
.format("parquet") // can be "orc", "json", "csv", etc.
.option("path", "path/to/destination/dir")
.start()- Kafka sink - 出力を Kafka の 1 つ以上のトピックに保存します。
writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "updates")
.start()- Foreach sink - 出力レコードに対して任意の計算を実行します。詳細については、このセクションの後半を参照してください。
writeStream
.foreach(...)
.start()- Console sink (デバッグ用) - トリガーごとにコンソール/標準出力に出力します。Append および Complete 出力モードの両方がサポートされています。これは、トリガーごとにすべての出力が収集され、ドライバーのメモリに格納されるため、低データ量でのデバッグ目的に使用する必要があります。
writeStream
.format("console")
.start()- Memory sink (デバッグ用) - 出力はメモリ内のテーブルとしてメモリに格納されます。Append および Complete 出力モードの両方がサポートされています。これは、トリガーごとにすべての出力が収集され、ドライバーのメモリに格納されるため、低データ量でのデバッグ目的に使用する必要があります。したがって、注意して使用してください。
writeStream
.format("memory")
.queryName("tableName")
.start()一部のシンクは、出力の永続性を保証せず、デバッグ目的のみを想定しているため、耐障害性がありません。以前の「耐障害性セマンティクス」セクションを参照してください。Spark のすべてのシンクの詳細を以下に示します。
| シンク | サポートされている出力モード | オプション | 耐障害性 | 注記 |
|---|---|---|---|---|
| File Sink | Append |
path: 出力ディレクトリへのパス。指定する必要があります。retention: 出力ファイルの生存期間 (TTL)。TTL より古いバッチがコミットされた出力ファイルは、最終的にメタデータログから除外されます。つまり、シンクの出力ディレクトリを読み取るリーダー クエリは、それらを処理しない場合があります。値を時間の文字列形式で指定できます。(例: "12h", "7d" など)。デフォルトでは無効です。ファイル形式固有のオプションについては、DataFrameWriter の関連メソッドを参照してください (Python/Scala/Java/R)。たとえば、"parquet" フォーマットのオプションについては、 DataFrameWriter.parquet() を参照してください。 |
はい (exactly-once) | パーティション化されたテーブルへの書き込みをサポートします。時間によるパーティショニングが役立つ場合があります。 |
| Kafka Sink | Append, Update, Complete | 「Kafka Integration Guide」を参照してください。 | はい (at-least-once) | 詳細については、「Kafka Integration Guide」を参照してください。 |
| Foreach Sink | Append, Update, Complete | なし | はい (at-least-once) | 詳細については、「次のセクション」を参照してください。 |
| ForeachBatch Sink | Append, Update, Complete | なし | 実装によります。 | 詳細については、「次のセクション」を参照してください。 |
| Console Sink | Append, Update, Complete |
numRows: トリガーごとに印刷する行数 (デフォルト: 20)truncate: 出力が長すぎる場合に切り捨てるかどうか (デフォルト: true) |
いいえ | |
| Memory Sink | Append, Complete | なし | いいえ。ただし、Complete モードでは、再起動されたクエリはテーブル全体を再作成します。 | テーブル名はクエリ名です。 |
クエリの実行を実際に開始するには start() を呼び出す必要があることに注意してください。これは、継続的に実行される実行のハンドルである StreamingQuery オブジェクトを返します。このオブジェクトを使用してクエリを管理できます。これは次のサブセクションで説明します。まずは、これらのすべてをいくつかの例で理解しましょう。
# ========== DF with no aggregations ==========
noAggDF = deviceDataDf.select("device").where("signal > 10")
# Print new data to console
noAggDF \
.writeStream \
.format("console") \
.start()
# Write new data to Parquet files
noAggDF \
.writeStream \
.format("parquet") \
.option("checkpointLocation", "path/to/checkpoint/dir") \
.option("path", "path/to/destination/dir") \
.start()
# ========== DF with aggregation ==========
aggDF = df.groupBy("device").count()
# Print updated aggregations to console
aggDF \
.writeStream \
.outputMode("complete") \
.format("console") \
.start()
# Have all the aggregates in an in-memory table. The query name will be the table name
aggDF \
.writeStream \
.queryName("aggregates") \
.outputMode("complete") \
.format("memory") \
.start()
spark.sql("select * from aggregates").show() # interactively query in-memory table// ========== DF with no aggregations ==========
val noAggDF = deviceDataDf.select("device").where("signal > 10")
// Print new data to console
noAggDF
.writeStream
.format("console")
.start()
// Write new data to Parquet files
noAggDF
.writeStream
.format("parquet")
.option("checkpointLocation", "path/to/checkpoint/dir")
.option("path", "path/to/destination/dir")
.start()
// ========== DF with aggregation ==========
val aggDF = df.groupBy("device").count()
// Print updated aggregations to console
aggDF
.writeStream
.outputMode("complete")
.format("console")
.start()
// Have all the aggregates in an in-memory table
aggDF
.writeStream
.queryName("aggregates") // this query name will be the table name
.outputMode("complete")
.format("memory")
.start()
spark.sql("select * from aggregates").show() // interactively query in-memory table// ========== DF with no aggregations ==========
Dataset<Row> noAggDF = deviceDataDf.select("device").where("signal > 10");
// Print new data to console
noAggDF
.writeStream()
.format("console")
.start();
// Write new data to Parquet files
noAggDF
.writeStream()
.format("parquet")
.option("checkpointLocation", "path/to/checkpoint/dir")
.option("path", "path/to/destination/dir")
.start();
// ========== DF with aggregation ==========
Dataset<Row> aggDF = df.groupBy("device").count();
// Print updated aggregations to console
aggDF
.writeStream()
.outputMode("complete")
.format("console")
.start();
// Have all the aggregates in an in-memory table
aggDF
.writeStream()
.queryName("aggregates") // this query name will be the table name
.outputMode("complete")
.format("memory")
.start();
spark.sql("select * from aggregates").show(); // interactively query in-memory table# ========== DF with no aggregations ==========
noAggDF <- select(where(deviceDataDf, "signal > 10"), "device")
# Print new data to console
write.stream(noAggDF, "console")
# Write new data to Parquet files
write.stream(noAggDF,
"parquet",
path = "path/to/destination/dir",
checkpointLocation = "path/to/checkpoint/dir")
# ========== DF with aggregation ==========
aggDF <- count(groupBy(df, "device"))
# Print updated aggregations to console
write.stream(aggDF, "console", outputMode = "complete")
# Have all the aggregates in an in memory table. The query name will be the table name
write.stream(aggDF, "memory", queryName = "aggregates", outputMode = "complete")
# Interactively query in-memory table
head(sql("select * from aggregates"))Foreach および ForeachBatch の使用
foreach および foreachBatch 操作を使用すると、ストリーミングクエリの出力に任意の操作と書き込みロジックを適用できます。ユースケースはわずかに異なります。foreach は行ごとにカスタム書き込みロジックを許可しますが、foreachBatch は各マイクロバッチの出力に対して任意の操作とカスタムロジックを許可します。それらの使用法をさらに詳しく理解しましょう。
ForeachBatch
foreachBatch(...) を使用すると、ストリーミングクエリの各マイクロバッチの出力データに対して実行される関数を指定できます。Spark 2.4 以降、これは Scala、Java、Python でサポートされています。マイクロバッチの出力データを含む DataFrame または Dataset と、マイクロバッチの一意の ID の 2 つのパラメータを取ります。
def foreach_batch_function(df, epoch_id):
# Transform and write batchDF
pass
streamingDF.writeStream.foreachBatch(foreach_batch_function).start()streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
// Transform and write batchDF
}.start()streamingDatasetOfString.writeStream().foreachBatch(
new VoidFunction2<Dataset<String>, Long>() {
public void call(Dataset<String> dataset, Long batchId) {
// Transform and write batchDF
}
}
).start();R はまだサポートされていません。
foreachBatch を使用すると、次のことができます。
- 既存のバッチデータソースの再利用 - 多くのストレージシステムでは、まだストリーミングシンクが利用できない場合がありますが、バッチクエリ用のデータライターはすでに存在する可能性があります。
foreachBatchを使用すると、各マイクロバッチの出力に対してバッチデータライターを使用できます。 - 複数の場所に書き込む - ストリーミングクエリの出力を複数の場所に書き込みたい場合は、出力 DataFrame/Dataset を複数回書き込むだけで済みます。ただし、書き込みの各試行で、出力データが再計算される可能性があります(入力データの再読み取りを含む)。再計算を避けるために、出力 DataFrame/Dataset をキャッシュし、複数の場所に書き込み、その後キャッシュを解除する必要があります。概要を以下に示します。
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
batchDF.persist()
batchDF.write.format(...).save(...) // location 1
batchDF.write.format(...).save(...) // location 2
batchDF.unpersist()
}- 追加の DataFrame 操作の適用 - Spark はこれらのケースで増分プランを生成できないため、ストリーミング DataFrame では多くの DataFrame および Dataset 操作がサポートされていません。
foreachBatchを使用すると、これらの操作の一部を各マイクロバッチ出力に適用できます。ただし、その操作を実行することのエンドツーエンドのセマンティクスを自分で理解する必要があります。
注意
- デフォルトでは、
foreachBatchは at-least-once の書き込み保証のみを提供します。ただし、関数に提供される batchId を使用して出力を重複排除し、exactly-once の保証を取得できます。 foreachBatchは、マイクロバッチ実行に根本的に依存する継続的処理モードでは機能しません。継続的モードでデータを書き込む場合は、代わりにforeachを使用してください。foreachBatchがステートフルストリーミングクエリと共に使用され、同じ DataFrame に対して複数の DataFrame アクション(df.count()の後にdf.collect()など)が実行される場合、クエリは複数回評価され、同じバッチ内で状態が複数回再ロードされるため、パフォーマンスが低下します。この場合、ユーザーは、再計算を回避するために、foreachBatchUDF(ユーザー定義関数)内で DataFrame に対してpersistおよびunpersistを呼び出すことを強くお勧めします。
Foreach
foreachBatch がオプションでない場合(たとえば、対応するバッチデータライターが存在しない、または継続的処理モード)、foreach を使用してカスタムライターロジックを表現できます。具体的には、書き込みロジックを open、process、および close の 3 つのメソッドに分割して表現できます。Spark 2.4 以降、foreach は Scala、Java、Python で利用可能です。
Python では、関数またはオブジェクトのいずれか 2 つの方法で foreach を呼び出すことができます。関数は処理ロジックを表現する簡単な方法を提供しますが、一部の入力データが再処理される原因となる障害が発生した場合に生成されたデータを重複排除することはできません。その状況では、オブジェクトで処理ロジックを指定する必要があります。
- まず、関数は行を入力として取ります。
def process_row(row):
# Write row to storage
pass
query = streamingDF.writeStream.foreach(process_row).start()- 次に、オブジェクトには process メソッドと、オプションで open および close メソッドがあります。
class ForeachWriter:
def open(self, partition_id, epoch_id):
# Open connection. This method is optional in Python.
pass
def process(self, row):
# Write row to connection. This method is NOT optional in Python.
pass
def close(self, error):
# Close the connection. This method in optional in Python.
pass
query = streamingDF.writeStream.foreach(ForeachWriter()).start()Scala では、ForeachWriter クラスを継承する必要があります (ドキュメント)。
streamingDatasetOfString.writeStream.foreach(
new ForeachWriter[String] {
def open(partitionId: Long, version: Long): Boolean = {
// Open connection
}
def process(record: String): Unit = {
// Write string to connection
}
def close(errorOrNull: Throwable): Unit = {
// Close the connection
}
}
).start()Java では、ForeachWriter クラスを継承する必要があります (ドキュメント)。
streamingDatasetOfString.writeStream().foreach(
new ForeachWriter<String>() {
@Override public boolean open(long partitionId, long version) {
// Open connection
}
@Override public void process(String record) {
// Write string to connection
}
@Override public void close(Throwable errorOrNull) {
// Close the connection
}
}
).start();R はまだサポートされていません。
実行セマンティクス ストリーミングクエリが開始されると、Spark は次の方法で関数またはオブジェクトのメソッドを呼び出します。
-
このオブジェクトの単一のコピーが、クエリ内のすべてのデータ生成を担当します。つまり、1 つのインスタンスが、分散して生成されたデータの 1 つのパーティションを処理する責任を負います。
-
このオブジェクトはシリアライズ可能である必要があります。各タスクは、提供されたオブジェクトのシリアライズ/デシリアライズされた新しいコピーを取得するためです。したがって、書き込みデータ(たとえば、接続を開く、トランザクションを開始するなど)の初期化は、
open()メソッドが呼び出された後に行われることを強くお勧めします。これは、タスクがデータを生成する準備ができたことを示します。 -
メソッドのライフサイクルは次のとおりです。
-
パーティション ID を持つ各パーティションについて
-
ストリーミングデータの各バッチ/エポックについて、エポック ID を使用します。
-
メソッド
open(partitionId, epochId)が呼び出されます。 -
open(...)が true を返した場合、パーティションとバッチ/エポック内の各行について、メソッドprocess(row)が呼び出されます。 -
メソッド
close(error)が、行の処理中に発生したエラー(存在する場合)と共に呼び出されます。
-
-
-
-
close()メソッド(存在する場合)は、open()メソッドが存在し、成功を返した場合(戻り値に関係なく)呼び出されます。ただし、JVM または Python プロセスが途中でクラッシュした場合は除きます。 -
注意: Spark は (partitionId, epochId) に対して同じ出力を保証しないため、(partitionId, epochId) で重複排除を達成することはできません。たとえば、ソースが何らかの理由で異なる数のパーティションを提供したり、Spark の最適化でパーティション数が変更されたりする場合などです。詳細については、SPARK-28650 を参照してください。重複排除が必要な場合は、
foreachBatchを試してください。
ストリーミングテーブル API
Spark 3.1 以降、DataStreamReader.table() を使用してテーブルをストリーミング DataFrame として読み取り、DataStreamWriter.toTable() を使用してストリーミング DataFrame をテーブルとして書き込むこともできます。
spark = ... # spark session
# Create a streaming DataFrame
df = spark.readStream \
.format("rate") \
.option("rowsPerSecond", 10) \
.load()
# Write the streaming DataFrame to a table
df.writeStream \
.option("checkpointLocation", "path/to/checkpoint/dir") \
.toTable("myTable")
# Check the table result
spark.read.table("myTable").show()
# Transform the source dataset and write to a new table
spark.readStream \
.table("myTable") \
.select("value") \
.writeStream \
.option("checkpointLocation", "path/to/checkpoint/dir") \
.format("parquet") \
.toTable("newTable")
# Check the new table result
spark.read.table("newTable").show()val spark: SparkSession = ...
// Create a streaming DataFrame
val df = spark.readStream
.format("rate")
.option("rowsPerSecond", 10)
.load()
// Write the streaming DataFrame to a table
df.writeStream
.option("checkpointLocation", "path/to/checkpoint/dir")
.toTable("myTable")
// Check the table result
spark.read.table("myTable").show()
// Transform the source dataset and write to a new table
spark.readStream
.table("myTable")
.select("value")
.writeStream
.option("checkpointLocation", "path/to/checkpoint/dir")
.format("parquet")
.toTable("newTable")
// Check the new table result
spark.read.table("newTable").show()SparkSession spark = ...
// Create a streaming DataFrame
Dataset<Row> df = spark.readStream()
.format("rate")
.option("rowsPerSecond", 10)
.load();
// Write the streaming DataFrame to a table
df.writeStream()
.option("checkpointLocation", "path/to/checkpoint/dir")
.toTable("myTable");
// Check the table result
spark.read().table("myTable").show();
// Transform the source dataset and write to a new table
spark.readStream()
.table("myTable")
.select("value")
.writeStream()
.option("checkpointLocation", "path/to/checkpoint/dir")
.format("parquet")
.toTable("newTable");
// Check the new table result
spark.read().table("newTable").show();R では利用できません。
詳細については、DataStreamReader (Python/Scala/Java ドキュメント) および DataStreamWriter (Python/Scala/Java ドキュメント) のドキュメントを確認してください。
トリガー
ストリーミングクエリのトリガー設定は、ストリーミングデータ処理のタイミングを定義します。クエリが固定バッチ間隔のマイクロバッチクエリとして実行されるか、継続的処理クエリとして実行されるかです。サポートされているトリガーの種類を以下に示します。
| トリガーの種類 | 説明 |
|---|---|
| 未指定 (デフォルト) | トリガー設定が明示的に指定されていない場合、デフォルトでは、クエリはマイクロバッチモードで実行されます。ここで、マイクロバッチは前のマイクロバッチの処理が完了次第生成されます。 |
| 固定間隔マイクロバッチ | クエリはマイクロバッチモードで実行され、マイクロバッチはユーザー指定の間隔で開始されます。
|
| 1 回限りのマイクロバッチ(非推奨) | クエリは、利用可能なすべてのデータを処理するために1 回のマイクロバッチを実行し、その後自動的に停止します。これは、定期的にクラスターを起動し、前回の期間以降に利用可能だったすべてのものを処理し、その後クラスターをシャットダウンしたいシナリオに役立ちます。場合によっては、これにより大幅なコスト削減につながる可能性があります。このトリガーは非推奨であり、ユーザーは Available-now micro-batch に移行することが推奨されます。これは、より良い処理保証、バッチの細かいスケール、およびウォーターマークの進行のより良い段階的処理(データなしバッチを含む)を提供するからです。 |
| Available-now マイクロバッチ | クエリの 1 回限りのマイクロバッチトリガーと同様に、クエリは利用可能なすべてのデータを処理し、その後自動的に停止します。違いは、ソースオプション(たとえば、ファイルソースの maxFilesPerTrigger または maxBytesPerTrigger)に基づいて、(おそらく) 複数のマイクロバッチでデータを処理することです。これにより、クエリの拡張性が向上します。
|
| 固定チェックポイント間隔での継続的処理 (実験的) |
クエリは、新しい低レイテンシの継続的処理モードで実行されます。詳細については、以下の「継続的処理」セクションを参照してください。 |
いくつかのコード例を以下に示します。
# Default trigger (runs micro-batch as soon as it can)
df.writeStream \
.format("console") \
.start()
# ProcessingTime trigger with two-seconds micro-batch interval
df.writeStream \
.format("console") \
.trigger(processingTime='2 seconds') \
.start()
# One-time trigger (Deprecated, encouraged to use Available-now trigger)
df.writeStream \
.format("console") \
.trigger(once=True) \
.start()
# Available-now trigger
df.writeStream \
.format("console") \
.trigger(availableNow=True) \
.start()
# Continuous trigger with one-second checkpointing interval
df.writeStream
.format("console")
.trigger(continuous='1 second')
.start()import org.apache.spark.sql.streaming.Trigger
// Default trigger (runs micro-batch as soon as it can)
df.writeStream
.format("console")
.start()
// ProcessingTime trigger with two-seconds micro-batch interval
df.writeStream
.format("console")
.trigger(Trigger.ProcessingTime("2 seconds"))
.start()
// One-time trigger (Deprecated, encouraged to use Available-now trigger)
df.writeStream
.format("console")
.trigger(Trigger.Once())
.start()
// Available-now trigger
df.writeStream
.format("console")
.trigger(Trigger.AvailableNow())
.start()
// Continuous trigger with one-second checkpointing interval
df.writeStream
.format("console")
.trigger(Trigger.Continuous("1 second"))
.start()import org.apache.spark.sql.streaming.Trigger
// Default trigger (runs micro-batch as soon as it can)
df.writeStream
.format("console")
.start();
// ProcessingTime trigger with two-seconds micro-batch interval
df.writeStream
.format("console")
.trigger(Trigger.ProcessingTime("2 seconds"))
.start();
// One-time trigger (Deprecated, encouraged to use Available-now trigger)
df.writeStream
.format("console")
.trigger(Trigger.Once())
.start();
// Available-now trigger
df.writeStream
.format("console")
.trigger(Trigger.AvailableNow())
.start();
// Continuous trigger with one-second checkpointing interval
df.writeStream
.format("console")
.trigger(Trigger.Continuous("1 second"))
.start();# Default trigger (runs micro-batch as soon as it can)
write.stream(df, "console")
# ProcessingTime trigger with two-seconds micro-batch interval
write.stream(df, "console", trigger.processingTime = "2 seconds")
# One-time trigger
write.stream(df, "console", trigger.once = TRUE)
# Continuous trigger is not yet supportedストリーミングクエリの管理
クエリの開始時に作成された StreamingQuery オブジェクトは、クエリの監視と管理に使用できます。
query = df.writeStream.format("console").start() # get the query object
query.id() # get the unique identifier of the running query that persists across restarts from checkpoint data
query.runId() # get the unique id of this run of the query, which will be generated at every start/restart
query.name() # get the name of the auto-generated or user-specified name
query.explain() # print detailed explanations of the query
query.stop() # stop the query
query.awaitTermination() # block until query is terminated, with stop() or with error
query.exception() # the exception if the query has been terminated with error
query.recentProgress # a list of the most recent progress updates for this query
query.lastProgress # the most recent progress update of this streaming queryval query = df.writeStream.format("console").start() // get the query object
query.id // get the unique identifier of the running query that persists across restarts from checkpoint data
query.runId // get the unique id of this run of the query, which will be generated at every start/restart
query.name // get the name of the auto-generated or user-specified name
query.explain() // print detailed explanations of the query
query.stop() // stop the query
query.awaitTermination() // block until query is terminated, with stop() or with error
query.exception // the exception if the query has been terminated with error
query.recentProgress // an array of the most recent progress updates for this query
query.lastProgress // the most recent progress update of this streaming queryStreamingQuery query = df.writeStream().format("console").start(); // get the query object
query.id(); // get the unique identifier of the running query that persists across restarts from checkpoint data
query.runId(); // get the unique id of this run of the query, which will be generated at every start/restart
query.name(); // get the name of the auto-generated or user-specified name
query.explain(); // print detailed explanations of the query
query.stop(); // stop the query
query.awaitTermination(); // block until query is terminated, with stop() or with error
query.exception(); // the exception if the query has been terminated with error
query.recentProgress(); // an array of the most recent progress updates for this query
query.lastProgress(); // the most recent progress update of this streaming queryquery <- write.stream(df, "console") # get the query object
queryName(query) # get the name of the auto-generated or user-specified name
explain(query) # print detailed explanations of the query
stopQuery(query) # stop the query
awaitTermination(query) # block until query is terminated, with stop() or with error
lastProgress(query) # the most recent progress update of this streaming query単一の SparkSession で任意の数のクエリを開始できます。これらはすべて、クラスターリソースを共有して並行して実行されます。sparkSession.streams() を使用して、現在アクティブなクエリを管理するために使用できる StreamingQueryManager (Python/Scala/Java ドキュメント) を取得できます。
spark = ... # spark session
spark.streams.active # get the list of currently active streaming queries
spark.streams.get(id) # get a query object by its unique id
spark.streams.awaitAnyTermination() # block until any one of them terminatesval spark: SparkSession = ...
spark.streams.active // get the list of currently active streaming queries
spark.streams.get(id) // get a query object by its unique id
spark.streams.awaitAnyTermination() // block until any one of them terminatesSparkSession spark = ...
spark.streams().active(); // get the list of currently active streaming queries
spark.streams().get(id); // get a query object by its unique id
spark.streams().awaitAnyTermination(); // block until any one of them terminatesNot available in R.ストリーミングクエリの監視
アクティブなストリーミングクエリを監視するには、いくつかの方法があります。Spark の Dropwizard Metrics サポートを使用して外部システムにメトリクスをプッシュするか、プログラムでアクセスできます。
インタラクティブなメトリクスの読み取り
streamingQuery.lastProgress() および streamingQuery.status() を使用して、アクティブなクエリの現在のステータスとメトリクスを直接取得できます。lastProgress() は、Scala および Java では StreamingQueryProgress オブジェクトを、Python では同じフィールドを持つ辞書を返します。ストリームの最後のトリガーの進行状況に関するすべての情報が含まれています。処理されたデータ、処理レート、レイテンシなどです。streamingQuery.recentProgress もあり、これは最後の数回の進行状況の配列を返します。
さらに、streamingQuery.status() は、Scala および Java では StreamingQueryStatus オブジェクトを、Python では同じフィールドを持つ辞書を返します。クエリが現在何を行っているかについての情報を提供します。トリガーがアクティブか、データが処理されているかなどです。
いくつかの例を以下に示します。
query = ... # a StreamingQuery
print(query.lastProgress)
'''
Will print something like the following.
{u'stateOperators': [], u'eventTime': {u'watermark': u'2016-12-14T18:45:24.873Z'}, u'name': u'MyQuery', u'timestamp': u'2016-12-14T18:45:24.873Z', u'processedRowsPerSecond': 200.0, u'inputRowsPerSecond': 120.0, u'numInputRows': 10, u'sources': [{u'description': u'KafkaSource[Subscribe[topic-0]]', u'endOffset': {u'topic-0': {u'1': 134, u'0': 534, u'3': 21, u'2': 0, u'4': 115}}, u'processedRowsPerSecond': 200.0, u'inputRowsPerSecond': 120.0, u'numInputRows': 10, u'startOffset': {u'topic-0': {u'1': 1, u'0': 1, u'3': 1, u'2': 0, u'4': 1}}}], u'durationMs': {u'getOffset': 2, u'triggerExecution': 3}, u'runId': u'88e2ff94-ede0-45a8-b687-6316fbef529a', u'id': u'ce011fdc-8762-4dcb-84eb-a77333e28109', u'sink': {u'description': u'MemorySink'}}
'''
print(query.status)
'''
Will print something like the following.
{u'message': u'Waiting for data to arrive', u'isTriggerActive': False, u'isDataAvailable': False}
'''val query: StreamingQuery = ...
println(query.lastProgress)
/* Will print something like the following.
{
"id" : "ce011fdc-8762-4dcb-84eb-a77333e28109",
"runId" : "88e2ff94-ede0-45a8-b687-6316fbef529a",
"name" : "MyQuery",
"timestamp" : "2016-12-14T18:45:24.873Z",
"numInputRows" : 10,
"inputRowsPerSecond" : 120.0,
"processedRowsPerSecond" : 200.0,
"durationMs" : {
"triggerExecution" : 3,
"getOffset" : 2
},
"eventTime" : {
"watermark" : "2016-12-14T18:45:24.873Z"
},
"stateOperators" : [ ],
"sources" : [ {
"description" : "KafkaSource[Subscribe[topic-0]]",
"startOffset" : {
"topic-0" : {
"2" : 0,
"4" : 1,
"1" : 1,
"3" : 1,
"0" : 1
}
},
"endOffset" : {
"topic-0" : {
"2" : 0,
"4" : 115,
"1" : 134,
"3" : 21,
"0" : 534
}
},
"numInputRows" : 10,
"inputRowsPerSecond" : 120.0,
"processedRowsPerSecond" : 200.0
} ],
"sink" : {
"description" : "MemorySink"
}
}
*/
println(query.status)
/* Will print something like the following.
{
"message" : "Waiting for data to arrive",
"isDataAvailable" : false,
"isTriggerActive" : false
}
*/StreamingQuery query = ...
System.out.println(query.lastProgress());
/* Will print something like the following.
{
"id" : "ce011fdc-8762-4dcb-84eb-a77333e28109",
"runId" : "88e2ff94-ede0-45a8-b687-6316fbef529a",
"name" : "MyQuery",
"timestamp" : "2016-12-14T18:45:24.873Z",
"numInputRows" : 10,
"inputRowsPerSecond" : 120.0,
"processedRowsPerSecond" : 200.0,
"durationMs" : {
"triggerExecution" : 3,
"getOffset" : 2
},
"eventTime" : {
"watermark" : "2016-12-14T18:45:24.873Z"
},
"stateOperators" : [ ],
"sources" : [ {
"description" : "KafkaSource[Subscribe[topic-0]]",
"startOffset" : {
"topic-0" : {
"2" : 0,
"4" : 1,
"1" : 1,
"3" : 1,
"0" : 1
}
},
"endOffset" : {
"topic-0" : {
"2" : 0,
"4" : 115,
"1" : 134,
"3" : 21,
"0" : 534
}
},
"numInputRows" : 10,
"inputRowsPerSecond" : 120.0,
"processedRowsPerSecond" : 200.0
} ],
"sink" : {
"description" : "MemorySink"
}
}
*/
System.out.println(query.status());
/* Will print something like the following.
{
"message" : "Waiting for data to arrive",
"isDataAvailable" : false,
"isTriggerActive" : false
}
*/query <- ... # a StreamingQuery
lastProgress(query)
'''
Will print something like the following.
{
"id" : "8c57e1ec-94b5-4c99-b100-f694162df0b9",
"runId" : "ae505c5a-a64e-4896-8c28-c7cbaf926f16",
"name" : null,
"timestamp" : "2017-04-26T08:27:28.835Z",
"numInputRows" : 0,
"inputRowsPerSecond" : 0.0,
"processedRowsPerSecond" : 0.0,
"durationMs" : {
"getOffset" : 0,
"triggerExecution" : 1
},
"stateOperators" : [ {
"numRowsTotal" : 4,
"numRowsUpdated" : 0
} ],
"sources" : [ {
"description" : "TextSocketSource[host: localhost, port: 9999]",
"startOffset" : 1,
"endOffset" : 1,
"numInputRows" : 0,
"inputRowsPerSecond" : 0.0,
"processedRowsPerSecond" : 0.0
} ],
"sink" : {
"description" : "org.apache.spark.sql.execution.streaming.ConsoleSink@76b37531"
}
}
'''
status(query)
'''
Will print something like the following.
{
"message" : "Waiting for data to arrive",
"isDataAvailable" : false,
"isTriggerActive" : false
}
'''非同期 API を使用したプログラムによるメトリクスのレポート
SparkSession に関連付けられたすべてのクエリを、StreamingQueryListener (Python/Scala/Java ドキュメント) をアタッチすることによっても非同期に監視できます。カスタム StreamingQueryListener オブジェクトを sparkSession.streams.addListener() でアタッチすると、クエリが開始および停止されたとき、およびアクティブなクエリで進行があったときにコールバックを受け取ります。以下に例を示します。
spark = ...
class Listener(StreamingQueryListener):
def onQueryStarted(self, event):
print("Query started: " + queryStarted.id)
def onQueryProgress(self, event):
print("Query made progress: " + queryProgress.progress)
def onQueryTerminated(self, event):
print("Query terminated: " + queryTerminated.id)
spark.streams.addListener(Listener())val spark: SparkSession = ...
spark.streams.addListener(new StreamingQueryListener() {
override def onQueryStarted(queryStarted: QueryStartedEvent): Unit = {
println("Query started: " + queryStarted.id)
}
override def onQueryTerminated(queryTerminated: QueryTerminatedEvent): Unit = {
println("Query terminated: " + queryTerminated.id)
}
override def onQueryProgress(queryProgress: QueryProgressEvent): Unit = {
println("Query made progress: " + queryProgress.progress)
}
})SparkSession spark = ...
spark.streams().addListener(new StreamingQueryListener() {
@Override
public void onQueryStarted(QueryStartedEvent queryStarted) {
System.out.println("Query started: " + queryStarted.id());
}
@Override
public void onQueryTerminated(QueryTerminatedEvent queryTerminated) {
System.out.println("Query terminated: " + queryTerminated.id());
}
@Override
public void onQueryProgress(QueryProgressEvent queryProgress) {
System.out.println("Query made progress: " + queryProgress.progress());
}
});Not available in R.Dropwizard を使用したメトリクスのレポート
Spark は、Dropwizard ライブラリを使用してメトリクスをレポートすることをサポートしています。Structured Streaming クエリのメトリクスもレポートされるようにするには、SparkSession で設定 spark.sql.streaming.metricsEnabled を明示的に有効にする必要があります。
spark.conf.set("spark.sql.streaming.metricsEnabled", "true")
# or
spark.sql("SET spark.sql.streaming.metricsEnabled=true")spark.conf.set("spark.sql.streaming.metricsEnabled", "true")
// or
spark.sql("SET spark.sql.streaming.metricsEnabled=true")spark.conf().set("spark.sql.streaming.metricsEnabled", "true");
// or
spark.sql("SET spark.sql.streaming.metricsEnabled=true");sql("SET spark.sql.streaming.metricsEnabled=true")この設定が有効になった後、SparkSession で開始されたすべてのクエリは、設定されている シンク(例: Ganglia、Graphite、JMX など)に Dropwizard を介してメトリクスをレポートします。
チェックポイントによる障害からの復旧
障害または意図的なシャットダウンの場合、以前のクエリの進行状況と状態を回復し、中断したところから続行できます。これは、チェックポイントと書き込み先入れログを使用して行われます。チェックポイントの場所でクエリを構成すると、クエリはすべての進行状況情報(つまり、トリガーごとに処理されたオフセットの範囲)と実行中の集計(たとえば、クイック例の単語数)をチェックポイントの場所に保存します。このチェックポイントの場所は、HDFS 互換ファイルシステム上のパスである必要があり、クエリを 開始 する際に DataStreamWriter のオプションとして設定できます。
aggDF \
.writeStream \
.outputMode("complete") \
.option("checkpointLocation", "path/to/HDFS/dir") \
.format("memory") \
.start()aggDF
.writeStream
.outputMode("complete")
.option("checkpointLocation", "path/to/HDFS/dir")
.format("memory")
.start()aggDF
.writeStream()
.outputMode("complete")
.option("checkpointLocation", "path/to/HDFS/dir")
.format("memory")
.start();write.stream(aggDF, "memory", outputMode = "complete", checkpointLocation = "path/to/HDFS/dir")ストリーミングクエリの変更後の復旧セマンティクス
同じチェックポイントの場所から再起動する際に、ストリーミングクエリで許可される変更には制限があります。以下は、許可されていない、または変更の効果が明確に定義されていない変更のいくつかの種類です。それらのすべてについて
-
許可という用語は、指定された変更を行うことができることを意味しますが、その効果のセマンティクスが明確に定義されているかどうかは、クエリと変更によって異なります。
-
許可されないという用語は、指定された変更を行うべきではないことを意味します。再起動されたクエリは、予期しないエラーで失敗する可能性が高いです。
sdfは、sparkSession.readStream で生成されたストリーミング DataFrame/Dataset を表します。
変更の種類
-
入力ソースの数または型の変更(つまり、異なるソース): これは許可されません。
-
入力ソースのパラメータの変更: これが許可されるかどうか、および変更のセマンティクスが明確に定義されているかどうかは、ソースとクエリによって異なります。以下にいくつかの例を示します。
-
レート制限の追加/削除/変更は許可されます:
spark.readStream.format("kafka").option("subscribe", "topic")からspark.readStream.format("kafka").option("subscribe", "topic").option("maxOffsetsPerTrigger", ...) -
サブスクライブされたトピック/ファイルの変更は、結果が予測不能であるため、一般的に許可されません:
spark.readStream.format("kafka").option("subscribe", "topic")からspark.readStream.format("kafka").option("subscribe", "newTopic")
-
-
出力シンクの種類の変更: いくつかの特定のシンクの組み合わせ間の変更は許可されます。これは、ケースバイケースで確認する必要があります。以下にいくつかの例を示します。
-
File sink から Kafka sink への変更は許可されます。Kafka は新しいデータのみを参照します。
-
Kafka sink から file sink への変更は許可されません。
-
Kafka sink から foreach への変更、またはその逆は許可されます。
-
-
出力シンクのパラメータの変更: これが許可されるかどうか、および変更のセマンティクスが明確に定義されているかどうかは、シンクとクエリによって異なります。以下にいくつかの例を示します。
-
ファイルシンクの出力ディレクトリの変更は許可されません:
sdf.writeStream.format("parquet").option("path", "/somePath")からsdf.writeStream.format("parquet").option("path", "/anotherPath") -
出力トピックの変更は許可されます:
sdf.writeStream.format("kafka").option("topic", "someTopic")からsdf.writeStream.format("kafka").option("topic", "anotherTopic") -
ユーザー定義の foreach シンク(つまり、
ForeachWriterコード)の変更は許可されますが、変更のセマンティクスはコードに依存します。
-
-
射影/フィルタ/マップライクな操作の変更: 一部のケースは許可されます。たとえば
-
フィルタの追加/削除は許可されます:
sdf.selectExpr("a")からsdf.where(...).selectExpr("a").filter(...)。 -
同じ出力スキーマを持つ射影の変更は許可されます:
sdf.selectExpr("stringColumn AS json").writeStreamからsdf.selectExpr("anotherStringColumn AS json").writeStream -
異なる出力スキーマを持つ射影の変更は条件付きで許可されます:
sdf.selectExpr("a").writeStreamからsdf.selectExpr("b").writeStreamは、出力シンクが"a"から"b"へのスキーマ変更を許可する場合にのみ許可されます。
-
-
ステートフル操作の変更: ストリーミングクエリの一部の操作は、結果を継続的に更新するために状態データを維持する必要があります。Structured Streaming は、状態データを耐障害性のあるストレージ(たとえば、HDFS、AWS S3、Azure Blob Storage)に自動的にチェックポイントし、再起動後に復元します。ただし、これは、状態データのスキーマが再起動間で同じままであることを前提としています。これは、ストリーミングクエリのステートフル操作の変更(追加、削除、またはスキーマ変更)は、再起動間で許可されないことを意味します。状態の回復を確実にするために、再起動間でスキーマを変更すべきではないステートフル操作のリストを以下に示します。
-
ストリーミング集計: たとえば、
sdf.groupBy("a").agg(...)。グループ化キーまたは集計の数または型の変更は許可されません。 -
ストリーミング重複排除: たとえば、
sdf.dropDuplicates("a")。重複排除列の数または型の変更は許可されません。 -
ストリーム-ストリーム結合: たとえば、
sdf1.join(sdf2, ...)(つまり、両方の入力がsparkSession.readStreamで生成されている場合)。スキーマまたは等価結合列の変更は許可されません。結合の種類(外部または内部)の変更は許可されません。結合条件のその他の変更は、定義が不明確です。 -
任意のステートフル操作: たとえば、
sdf.groupByKey(...).mapGroupsWithState(...)またはsdf.groupByKey(...).flatMapGroupsWithState(...)。ユーザー定義の状態のスキーマおよびタイムアウトの型の変更は許可されません。ユーザー定義の状態マッピング関数内の変更は許可されますが、変更のセマンティックな効果はユーザー定義のロジックに依存します。状態スキーマの変更を実際にサポートしたい場合は、スキーマ移行をサポートするエンコード/デコードスキームを使用して、複雑な状態データ構造をバイトに明示的にエンコード/デコードできます。たとえば、状態を Avro エンコードバイトとして保存する場合、バイナリ状態は常に正常に復元されるため、クエリの再起動間で Avro-状態スキーマを変更することは自由です。
-