Spark Release 0.8.0
Apache Spark 0.8.0 は、多くの新機能と使いやすさの向上を含むメジャーリリースです。また、Apacheインキュベーターからの最初のリリースでもあります。67人の開発者と24社からの貢献による、これまでのSparkで最大のリリースです。
Spark 0.8.0 は、ソースパッケージ(4 MB tar.gz)または、Hadoop 1 / CDH3またはCDH4 用のビルド済みパッケージ(125 MB tar.gz)としてダウンロードできます。リリース署名とチェックサムは、公式のApacheダウンロードサイトで入手できます。
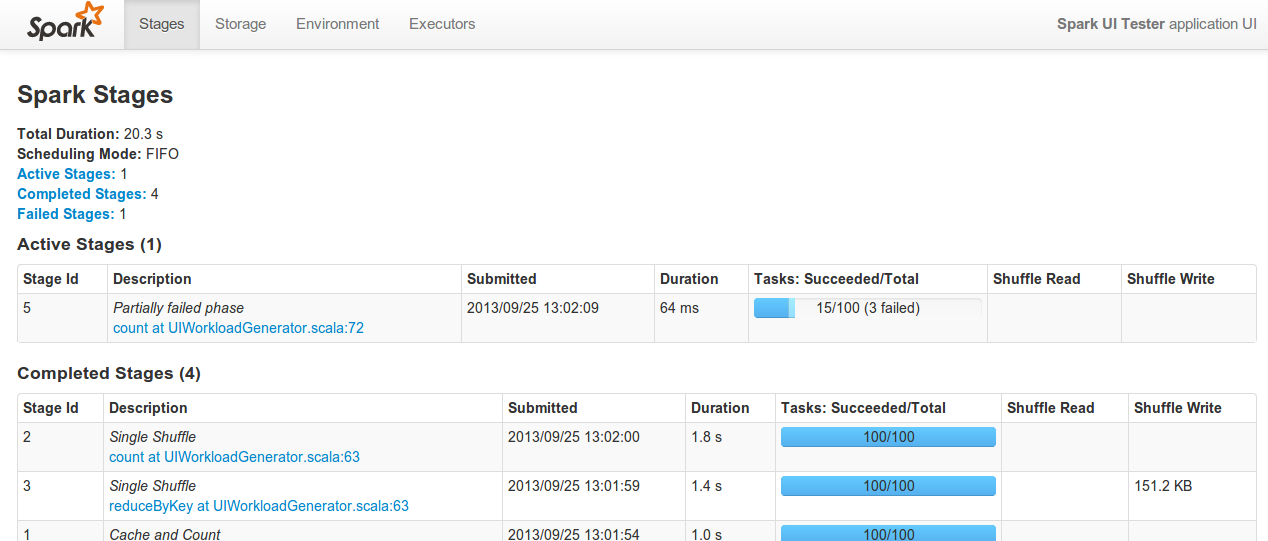
モニタリングUIとメトリクス
Sparkは、Web UI(デフォルトではドライバーノードのポート4040)で様々なモニタリングデータを表示するようになりました。新しいジョブダッシュボードには、実行中、成功、失敗したジョブの情報が含まれており、タスク実行時間、シャッフルデータ、ガベージコレクションをカバーするパーセンタイル統計も含まれています。既存のストレージダッシュボードは拡張され、エグゼキューターごとの合計ストレージとタスク情報を表示する追加ページが追加されました。最後に、新しいメトリクスライブラリは、JMXやGangliaを含む様々なAPIを通じて内部Sparkメトリクスを公開します。
機械学習ライブラリ
このリリースでは、Spark用の高品質な機械学習および最適化アルゴリズムの標準ライブラリであるMLlibが導入されました。MLlibは、UC Berkeley MLbaseプロジェクトとの協力により開発されました。現在のライブラリには、サポートベクターマシン(SVM)、ロジスティック回帰、線形回帰のいくつかの正則化バリアント、クラスタリングアルゴリズム(KMeans)、および交互最小二乗法協調フィルタリングを含む7つのアルゴリズムが含まれています。
Pythonの改善
Python APIは、以前は欠けていた多くの機能で拡張されました。これには、異なるストレージレベル、サンプリング、および様々な欠けていたRDD演算子へのサポートが含まれます。また、IPython Notebookを含むIPythonでのSparkの実行、およびWindowsでのPySparkの実行もサポートされました。
Hadoop YARNサポート
Spark 0.8では、YARNクラスタでスタンドアロンSparkジョブを実行するためのサポートが大幅に改善されました。YARNサポートは実験的なものではなくなり、メインラインSparkの一部となりました。セキュアなYARNクラスタに対して実行するためのサポートも追加されました。
リニューアルされたジョブスケジューラ
Sparkの内部ジョブスケジューラはリファクタリングされ、より洗練されたスケジューリングポリシーを含むように拡張されました。特に、フェアスケジューラの実装により、複数のユーザーがSparkインスタンスを共有できるようになり、実行時間の長いジョブが並列実行されている場合でも、短いジョブを実行するユーザーが良いパフォーマンスを得られるようになります。トポロジー認識スケジューリングのサポートが拡張され、ラックローカリティを考慮する機能や、単一マシン上の複数のエグゼキューターのサポートが含まれるようになりました。
デプロイとリンクの容易化
ユーザープログラムは、Hadoopのバージョンに関係なくSparkにリンクできるようになりました。これは、特定のHadoopバージョン用にspark-coreのバージョンを公開する必要がなくなったためです。異なるHadoopバージョンに対するリンク方法の説明は、こちらに記載されています。
EC2機能の拡張
SparkのEC2スクリプトは、任意の可用性ゾーンで起動できるようになりました。また、より新しい「HVM」アーキテクチャを使用するEC2インスタンスタイプもサポートされるようになりました。これには、クラスターコンピューティング(cc1/cc2)ファミリーのインスタンスタイプが含まれます。Sparkと並行して新しいバージョンのHDFSを実行するためのサポートも追加されました。最後に、最新リリースだけでなく、Sparkのメンテナンスリリースでクラスターを起動する機能が追加されました。
ドキュメントの改善
このリリースでは、クラスターハードウェアのプロビジョニングや一般的なHadoopディストリビューションとの相互運用性に関するドキュメントが追加されました。MLlibの機械学習機能や新しいクラスターモニタリング機能に関するドキュメントも含まれています。既存のドキュメントは、Sparkのビルドとデプロイの変更を反映するように更新されました。
その他の改善
unpersistを使用してRDDをメモリから手動で削除できるようになりました。- RDDクラスには、
takeOrdered、zipPartitions、topといった新しい操作が含まれています。 - Sparkワークロードのアーカイブ可能なログを生成するために、
JobLoggerクラスが追加されました。 RDD.coalesce関数は、ローカリティを考慮するようになりました。RDD.pipe関数は、子プロセスに環境変数を渡すことをサポートするように拡張されました。- Hadoopの
save関数は、オプションの圧縮コーデックをサポートするようになりました。 - クラスターへのデプロイを容易にするために、Javaランタイムのみに依存するSparkのバイナリディストリビューションを作成できるようになりました。
- 例のビルドはコアビルドから分離され、依存関係の競合の可能性が大幅に減少しました。
- Spark StreamingのTwitter APIは、Spark 0.7.0の非推奨となったユーザー名/パスワード認証ではなく、OAuth認証を使用するように更新されました。
- Java、Scala、PythonでのPageRank実装、HBaseおよびCassandraへのアクセス例、MLlibの例など、いくつかの新しい例ジョブが追加されました。
- Mesosでの実行サポートが改善されました。SparkアセンブリJARをMesosジョブの一部としてデプロイできるようになり、各マシンにSparkを事前にインストールする必要がなくなりました。デフォルトのMesosバージョンも0.13に更新されました。
- このリリースには、PySparkとジョブスケジューラの様々な最適化が含まれています。
互換性
- このリリースでは、Sparkのパッケージ名が「org.apache.spark」に変更されました。そのため、Spark 0.7からアップグレードするユーザーは、インポートを適宜調整する必要があります。さらに、
RDDクラスはorg.apache.spark.rddパッケージに移動されました(以前はトップレベルパッケージにありました)。Mavenを通じて公開されるSparkアーティファクトも、新しいパッケージ名に変更されました。 - Java APIでは、Scalaの
Optionクラスの使用は、GuavaライブラリのOptionalに置き換えられました。 - 任意のHadoopバージョンに対してSparkにリンクすることが可能になりました。これは、Hadoopバージョンに対して
spark-coreを再ビルドする代わりに、hadoop-clientへの依存関係を指定することで実現できます。詳細はこちらのドキュメントを参照してください。 - Sparkをビルドする場合、
packageの代わりにsbt/sbt assemblyを実行する必要があります。
クレジット
Spark 0.8.0は、これまでにない最大の貢献者チームによって実現されました。このリリースには以下の開発者が貢献しました。
- Andrew Ash – ドキュメント、コードクリーンアップ、ロギング改善
- Mikhail Bautin – バグ修正
- Konstantin Boudnik – Mavenビルド、バグ修正、ドキュメント
- Ian Buss – sbt設定改善
- Evan Chan – API改善、バグ修正、ドキュメント
- Lian Cheng – バグ修正
- Tathagata Das – ストリーミングレシーバーのパフォーマンス改善とストリーミングバグ修正
- Aaron Davidson – Python改善、バグ修正、単体テスト
- Giovanni Delussu – RDDのcoalesce機能
- Joseph E. Gonzalez – zipPartitionsの改善
- Karen Feng – Web UIへのいくつかの改善
- Andy Feng – HDFSメトリクス
- Ali Ghodsi – 設定改善とローカリティ対応coalesce
- Christoph Grothaus – バグ修正
- Thomas Graves – セキュアYARNクラスタのサポートと様々なYARN関連の改善
- Stephen Haberman – バグ修正、ドキュメント、コードクリーンアップ
- Mark Hamstra – バグ修正とMavenビルド
- Benjamin Hindman – Mesos互換性とドキュメント
- Liang-Chi Hsieh – ビルドとYARNモードでのバグ修正
- Shane Huang – シャッフル改善、バグ修正
- Ethan Jewett – Spark/HBase例
- Holden Karau – バグ修正とEC2改善
- Kody Koeniger – JDBV RDD実装
- Andy Konwinski – ドキュメント
- Jey Kottalam – PySpark最適化、Hadoop非依存ビルド(リード)、バグ修正
- Andrey Kouznetsov – バグ修正
- S. Kumar – Spark Streaming例
- Ryan LeCompte – topKメソッド最適化とシリアライゼーション改善
- Gavin Li – 圧縮コーデックとpipeサポート
- Harold Lim – フェアスケジューラ
- Dmitriy Lyubimov – バグ修正
- Chris Mattmann – Apacheメンター
- David McCauley – JSON API改善
- Sean McNamara –
takeOrdered関数の追加、バグ修正、ビルド修正 - Mridul Muralidharan – YARN統合(リード)、スケジューラ改善
- Marc Mercer – UI JSON出力への改善
- Christopher Nguyen – バグ修正
- Erik van Oosten – 例修正
- Kay Ousterhout – スケジューラ回帰の修正とバグ修正
- Xinghao Pan – MLLibへの貢献
- Hiral Patel – バグ修正
- James Phillpotts – SparkストリーミングのTwitter API更新
- Nick Pentreath – scala PageRank例、bagel改善、いくつかのJava例
- Alexander Pivovarov – ロギング改善とMavenビルド
- Mike Potts – 設定改善
- Rohit Rai – Spark/Cassandra例
- Imran Rashid – バグ修正とUI改善
- Charles Reiss – バグ修正、コードクリーンアップ、パフォーマンス改善
- Josh Rosen – Python API改善、Java API改善、EC2スクリプト、バグ修正
- Henry Saputra – Apacheメンター
- Jerry Shao – バグ修正、メトリクスシステム
- Prashant Sharma – ドキュメント
- Mingfei Shi – jobloggerとバグ修正
- Andre Schumacher – いくつかのPySpark機能
- Ginger Smith – MLLibへの貢献
- Evan Sparks – MLLibへの貢献
- Ram Sriharsha – バグ修正とRDD削除機能
- Ameet Talwalkar – MLlibへの貢献
- Roman Tkalenko – コードリファクタリングとクリーンアップ
- Chu Tong – Java PageRankアルゴリズムとbashスクリプトのバグ修正
- Shivaram Venkataraman – バグ修正、MLLibへの貢献、nettyシャッフル修正、Java API追加
- Patrick Wendell – リリースマネージャー、バグ修正、ドキュメント、メトリクスシステム、Web UI
- Andrew Xia – フェアスケジューラ(リード)、メトリクスシステム、UI改善
- Reynold Xin – シャッフル改善、バグ修正、コードリファクタリング、ユーザビリティ改善、MLLibへの貢献
- Matei Zaharia – MLLibへの貢献、ドキュメント、例、UI改善、PySpark改善、バグ修正
- Wu Zeming – スケジューラのバグ修正
- Bill Zhao – ログメッセージ改善
貢献していただいた皆様、ありがとうございました!このリリースのリリースマネージャーを務めてくれたPatrick Wendellには、特に感謝いたします。
最新ニュース
- Spark 3.5.6 リリース (2025年5月29日)
- Spark 4.0.0 リリース (2025年5月23日)
- Spark 3.5.5 リリース (2025年2月27日)
- Spark 3.5.4 リリース (2024年12月20日)
