Web UI
Apache Spark は、Spark クラスターの状態とリソース消費を監視するために使用できる一連の Web ユーザーインターフェイス (UI) を提供します。
目次
ジョブタブ
ジョブタブには、Spark アプリケーション内のすべてのジョブの概要ページと、各ジョブの詳細ページが表示されます。概要ページには、すべてのジョブの状態、期間、進捗状況、および全体的なイベントタイムラインなどのハイレベルな情報が表示されます。概要ページでジョブをクリックすると、そのジョブの詳細ページが表示されます。詳細ページには、さらにイベントタイムライン、DAG の視覚化、およびジョブのすべてのステージが表示されます。
このセクションに表示される情報は以下のとおりです。
- ユーザー: 現在の Spark ユーザー
- 開始日時: Spark アプリケーションの起動時間
- 総稼働時間: Spark アプリケーションが開始されてからの時間
- スケジューリングモード: ジョブスケジューリングを参照してください。
- ステータスごとのジョブ数: アクティブ、完了、失敗

- イベントタイムライン: エグゼキュータ (追加、削除) およびジョブに関連するイベントを時系列で表示します。

- ステータスごとのジョブ詳細: ジョブ ID、説明 (詳細ジョブページへのリンク付き)、送信日時、期間、ステージの概要、タスクの進捗バーなど、ジョブの詳細情報を表示します。

特定のジョブをクリックすると、そのジョブの詳細情報を確認できます。
ジョブ詳細
このページには、ジョブ ID で識別される特定のジョブの詳細が表示されます。
- ジョブステータス: (実行中、成功、失敗)
- ステータスごとのステージ数 (アクティブ、保留中、完了、スキップ、失敗)
- 関連 SQL クエリ: このジョブの SQL タブへのリンク
- イベントタイムライン: エグゼキュータ (追加、削除) およびジョブのステージに関連するイベントを時系列で表示します。

- DAG 視覚化: このジョブの有向非巡回グラフ (DAG) の視覚的な表現。頂点は RDD または DataFrame を表し、エッジは RDD に適用される操作を表します。
sc.parallelize(1 to 100).toDF.count()の DAG 視覚化の例

- ステージのリスト (ステータス別: アクティブ、保留中、完了、スキップ、失敗)
- ステージ ID
- ステージの説明
- 送信日時
- ステージの期間
- タスク進捗バー
- 入力: このステージでストレージから読み取られたバイト数
- 出力: このステージでストレージに書き込まれたバイト数
- シャフル読み取り: 合計シャフルバイト数と読み取られたレコード数。ローカルで読み取られたデータとリモートエグゼキュータから読み取られたデータの両方が含まれます。
- シャフル書き込み: 次のステージのシャフルで読み取られるためにディスクに書き込まれたバイト数とレコード数。

ステージタブ
ステージタブには、Spark アプリケーション内のすべてのジョブのすべてのステージの現在の状態を示す概要ページが表示されます。
ページの先頭には、ステータスごとのステージの合計数 (アクティブ、保留中、完了、スキップ、失敗) を含む概要があります。

フェアスケジューリングモードでは、プールプロパティを表示するテーブルがあります。

その後に、ステータスごとのステージ詳細 (アクティブ、保留中、完了、スキップ、失敗) が続きます。アクティブなステージでは、キルリンクを使用してステージをキルできます。失敗したステージでのみ、失敗理由が表示されます。タスクの詳細は、説明をクリックすることでアクセスできます。

ステージ詳細
ステージ詳細ページには、すべてのタスクにわたる総時間、データローカリティの概要、シャフル読み取りサイズ/レコード、および関連ジョブ ID などの情報が含まれています。

また、このステージの有向非巡回グラフ (DAG) の視覚的な表現もあります。頂点は RDD または DataFrame を表し、エッジは適用される操作を表します。ノードは DAG 視覚化で操作スコープごとにグループ化され、操作スコープ名 (BatchScan、WholeStageCodegen、Exchange など) でラベル付けされます。特に、Whole Stage Code Generation 操作はコード生成 ID で注釈付けされます。Spark DataFrame または SQL 実行に属するステージの場合、これにより、ステージ実行の詳細を Web UI SQL タブページで SQL プラングラフと実行プランが報告される関連詳細にクロス参照できます。

すべてのタスクの集計メトリクスは、テーブルとタイムラインで表されます。
- タスクのデシリアライゼーション時間
- タスクの期間.
- GC 時間 は、JVM のガベージコレクションの総時間です。
- 結果シリアライゼーション時間 は、エグゼキュータでタスクの結果をドライバーに送信する前にシリアライズするのに費やされた時間です。
- 結果取得時間 は、ドライバーがワーカーからタスクの結果を取得するのに費やす時間です。
- スケジューラ遅延 は、タスクが実行のためにスケジュールされるのを待つ時間です。
- ピーク実行メモリ は、シャフル、集計、結合中に作成された内部データ構造によって使用された最大メモリです。
- シャフル読み取りサイズ/レコード。合計シャフルバイト数。ローカルで読み取られたデータとリモートエグゼキュータから読み取られたデータが含まれます。
- シャフル読み取り待機時間 は、タスクがリモートマシンからシャフルデータを読み取るのを待ってブロックされた時間です。
- シャフルリモート読み取り は、リモートエグゼキュータから読み取られた合計シャフルバイト数です。
- シャフル書き込み時間 は、タスクがシャフルデータを書き込むのに費やされた時間です。
- シャフルスピル (メモリ) は、メモリ内のシャフルデータのデシリアライズされた形式のサイズです。
- シャフルスピル (ディスク) は、ディスク上のデータのシリアライズされた形式のサイズです。

エグゼキュータごとの集計メトリクスは、エグゼキュータごとに集計された同じ情報を示します。

アキュムレータ は、共有変数の型です。これは、さまざまな変換内で更新できるミュータブルな変数を提供します。アキュムレータは名前あり/なしで作成できますが、表示されるのは名前付きアキュムレータのみです。

タスクの詳細は、基本的に概要セクションと同じ情報を含みますが、タスクごとに詳細化されています。また、ログを確認するためのリンクや、何らかの理由で失敗した場合のタスク試行回数も含まれます。名前付きアキュムレータがある場合、ここでは各タスクの終わりにアキュムレータの値を確認できます。

ストレージタブ
ストレージタブには、アプリケーションで永続化された RDD および DataFrame (存在する場合) が表示されます。概要ページには、すべての RDD のストレージレベル、サイズ、パーティションが表示され、詳細ページには、RDD または DataFrame のすべてのパーティションのサイズと使用されているエグゼキュータが表示されます。
scala> import org.apache.spark.storage.StorageLevel._
import org.apache.spark.storage.StorageLevel._
scala> val rdd = sc.range(0, 100, 1, 5).setName("rdd")
rdd: org.apache.spark.rdd.RDD[Long] = rdd MapPartitionsRDD[1] at range at <console>:27
scala> rdd.persist(MEMORY_ONLY_SER)
res0: rdd.type = rdd MapPartitionsRDD[1] at range at <console>:27
scala> rdd.count
res1: Long = 100
scala> val df = Seq((1, "andy"), (2, "bob"), (2, "andy")).toDF("count", "name")
df: org.apache.spark.sql.DataFrame = [count: int, name: string]
scala> df.persist(DISK_ONLY)
res2: df.type = [count: int, name: string]
scala> df.count
res3: Long = 3

上記の例を実行した後、ストレージタブに 2 つの RDD がリストされていることがわかります。ストレージレベル、パーティション数、メモリオーバーヘッドなどの基本情報が提供されています。新しく永続化された RDD または DataFrame は、マテリアライズされる前にタブに表示されないことに注意してください。特定の RDD または DataFrame を監視するには、アクション操作がトリガーされていることを確認してください。

RDD 名「rdd」をクリックすると、クラスター上のデータ分散などのデータ永続化の詳細を取得できます。
環境タブ
環境タブには、JVM、Spark、およびシステムプロパティを含む、さまざまな環境および構成変数の値が表示されます。

この環境ページは 5 つの部分で構成されています。プロパティが正しく設定されているかどうかを確認するのに役立ちます。最初の部分「ランタイム情報」には、Java および Scala のバージョンなどのランタイムプロパティが含まれています。2 番目の部分「Spark プロパティ」には、「spark.app.name」や「spark.driver.memory」などのアプリケーションプロパティがリストされています。

「Hadoop プロパティ」リンクをクリックすると、Hadoop および YARN に関連するプロパティが表示されます。「spark.hadoop.*」などのプロパティは、この部分ではなく「Spark プロパティ」に表示されることに注意してください。

「システムプロパティ」は、JVM に関する詳細情報を示します。

最後の部分「クラスパスエントリ」は、さまざまなソースからロードされたクラスをリストしており、クラスの競合を解決するのに非常に役立ちます。
エグゼキュータタブ
エグゼキュータタブには、アプリケーションのために作成されたエグゼキュータに関する概要情報 (メモリおよびディスクの使用量、タスクおよびシャフル情報を含む) が表示されます。ストレージメモリ列には、データのキャッシュに使用されるメモリ量と予約済みのメモリ量が表示されます。

エグゼキュータタブは、リソース情報 (各エグゼキュータによって使用されるメモリ、ディスク、コアの量) だけでなく、パフォーマンス情報 (GC 時間とシャフル情報) も提供します。

エグゼキュータ 0 の「stderr」リンクをクリックすると、コンソールで標準エラーログの詳細が表示されます。

エグゼキュータ 0 の「スレッドダンプ」リンクをクリックすると、エグゼキュータ 0 の JVM のスレッドダンプが表示され、パフォーマンス分析に非常に役立ちます。
SQLタブ
アプリケーションが Spark SQL クエリを実行する場合、SQL タブには、クエリの期間、ジョブ、物理プランおよび論理プランなどの情報が表示されます。ここでは、このタブを説明するための簡単な例を含めます。
scala> val df = Seq((1, "andy"), (2, "bob"), (2, "andy")).toDF("count", "name")
df: org.apache.spark.sql.DataFrame = [count: int, name: string]
scala> df.count
res0: Long = 3
scala> df.createGlobalTempView("df")
scala> spark.sql("select name,sum(count) from global_temp.df group by name").show
+----+----------+
|name|sum(count)|
+----+----------+
|andy| 3|
| bob| 2|
+----+----------+

これで、上記の 3 つのデータフレーム/SQL オペレーターがリストに表示されます。最後のクエリの「show at <console>: 24」リンクをクリックすると、クエリ実行の DAG と詳細を確認できます。

クエリ詳細ページには、クエリ実行時間、その期間、関連ジョブのリスト、およびクエリ実行 DAG に関する情報が表示されます。最初のブロック「WholeStageCodegen (1)」は、複数のオペレーター (「LocalTableScan」と「HashAggregate」) を 1 つの Java 関数にコンパイルしてパフォーマンスを向上させ、行数やスピルサイズなどのメトリクスがブロックにリストされています。ブロック名のアノテーション「(1)」はコード生成 ID です。2 番目のブロック「Exchange」は、シャフル交換に関するメトリクスを表示します。これには、書き込まれたシャフルレコード数、合計データサイズなどが含まれます。

下部にある「詳細」リンクをクリックすると、Spark がクエリを解析、分析、最適化、および実行する方法を示す論理プランと物理プランが表示されます。Whole Stage Code Generation 最適化の対象となる物理プランのステップには、アスタリスクとコード生成 ID がプレフィックスとして付けられています。例: 「*(1) LocalTableScan」。
SQLメトリクス
SQL オペレーターのメトリクスは、物理オペレーターのブロックに表示されます。SQL メトリクスは、各オペレーターの実行詳細を掘り下げたい場合に役立ちます。たとえば、「出力行数」は、Filter オペレーターの後に何行が出力されるかを示し、「Exchange」オペレーターの「シャフルバイト書き込み合計」は、シャフルによって書き込まれたバイト数を示します。
SQL メトリクスのリストを以下に示します。
| SQLメトリクス | 意味 | オペレーター |
|---|---|---|
出力行数 | オペレーターの出力行数 | 集計オペレーター、結合オペレーター、サンプル、範囲、スキャンオペレーター、フィルターなど。 |
データサイズ | オペレーターのブロードキャスト/シャフル/収集されたデータのサイズ | BroadcastExchange、ShuffleExchange、Subquery |
収集時間 | データの収集に費やされた時間 | BroadcastExchange、Subquery |
スキャン時間 | データのスキャンに費やされた時間 | ColumnarBatchScan、FileSourceScan |
メタデータ時間 | パーティション数、ファイル数などのメタデータを取得するのに費やされた時間 | FileSourceScan |
シャフルバイト書き込み | 書き込まれたバイト数 | CollectLimit、TakeOrderedAndProject、ShuffleExchange |
シャフルレコード書き込み | 書き込まれたレコード数 | CollectLimit、TakeOrderedAndProject、ShuffleExchange |
シャフル書き込み時間 | シャフル書き込みに費やされた時間 | CollectLimit、TakeOrderedAndProject、ShuffleExchange |
リモートブロック読み取り | リモートで読み取られたブロック数 | CollectLimit、TakeOrderedAndProject、ShuffleExchange |
リモートバイト読み取り | リモートで読み取られたバイト数 | CollectLimit、TakeOrderedAndProject、ShuffleExchange |
リモートからディスクへのバイト読み取り | リモートからローカルディスクに読み取られたバイト数 | CollectLimit、TakeOrderedAndProject、ShuffleExchange |
ローカルブロック読み取り | ローカルで読み取られたブロック数 | CollectLimit、TakeOrderedAndProject、ShuffleExchange |
ローカルバイト読み取り | ローカルで読み取られたバイト数 | CollectLimit、TakeOrderedAndProject、ShuffleExchange |
フェッチ待機時間 | データのフェッチに費やされた時間 (ローカルおよびリモート) | CollectLimit、TakeOrderedAndProject、ShuffleExchange |
読み取られたレコード | 読み取られたレコード数 | CollectLimit、TakeOrderedAndProject、ShuffleExchange |
ソート時間 | ソートに費やされた時間 | Sort |
ピークメモリ | オペレーターでのピークメモリ使用量 | Sort、HashAggregate |
スピルサイズ | オペレーターでメモリからディスクにスピルされたバイト数 | Sort、HashAggregate |
集計ビルド時間 | 集計に費やされた時間 | HashAggregate、ObjectHashAggregate |
平均ハッシュプローブバケットリストイテレータ | 集計中のルックアップごとの平均バケットリストイテレータ数 | HashAggregate |
ビルドサイドのデータサイズ | 構築されたハッシュマップのサイズ | ShuffledHashJoin |
ハッシュマップ構築時間 | ハッシュマップの構築に費やされた時間 | ShuffledHashJoin |
タスクコミット時間 | 書き込みが成功した後、タスクの出力をコミットするのに費やされた時間 | ファイルベースのテーブルに対する任意の書き込み操作 |
ジョブコミット時間 | 書き込みが成功した後、ジョブの出力をコミットするのに費やされた時間 | ファイルベースのテーブルに対する任意の書き込み操作 |
Python ワーカーに送信されたデータ | Python ワーカーに送信されたシリアライズ済みデータのバイト数 | Python UDF、Pandas UDF、Pandas Functions API、Python データソース |
Python ワーカーから返されたデータ | Python ワーカーから受信したシリアライズ済みデータのバイト数 | Python UDF、Pandas UDF、Pandas Functions API、Python データソース |
構造化ストリーミングタブ
マイクロバッチモードで構造化ストリーミングジョブを実行すると、Web UI に構造化ストリーミングタブが利用可能になります。概要ページには、実行中および完了したクエリの簡単な統計情報が表示されます。また、失敗したクエリの最新の例外を確認することもできます。詳細な統計情報については、テーブル内の「実行 ID」をクリックしてください。

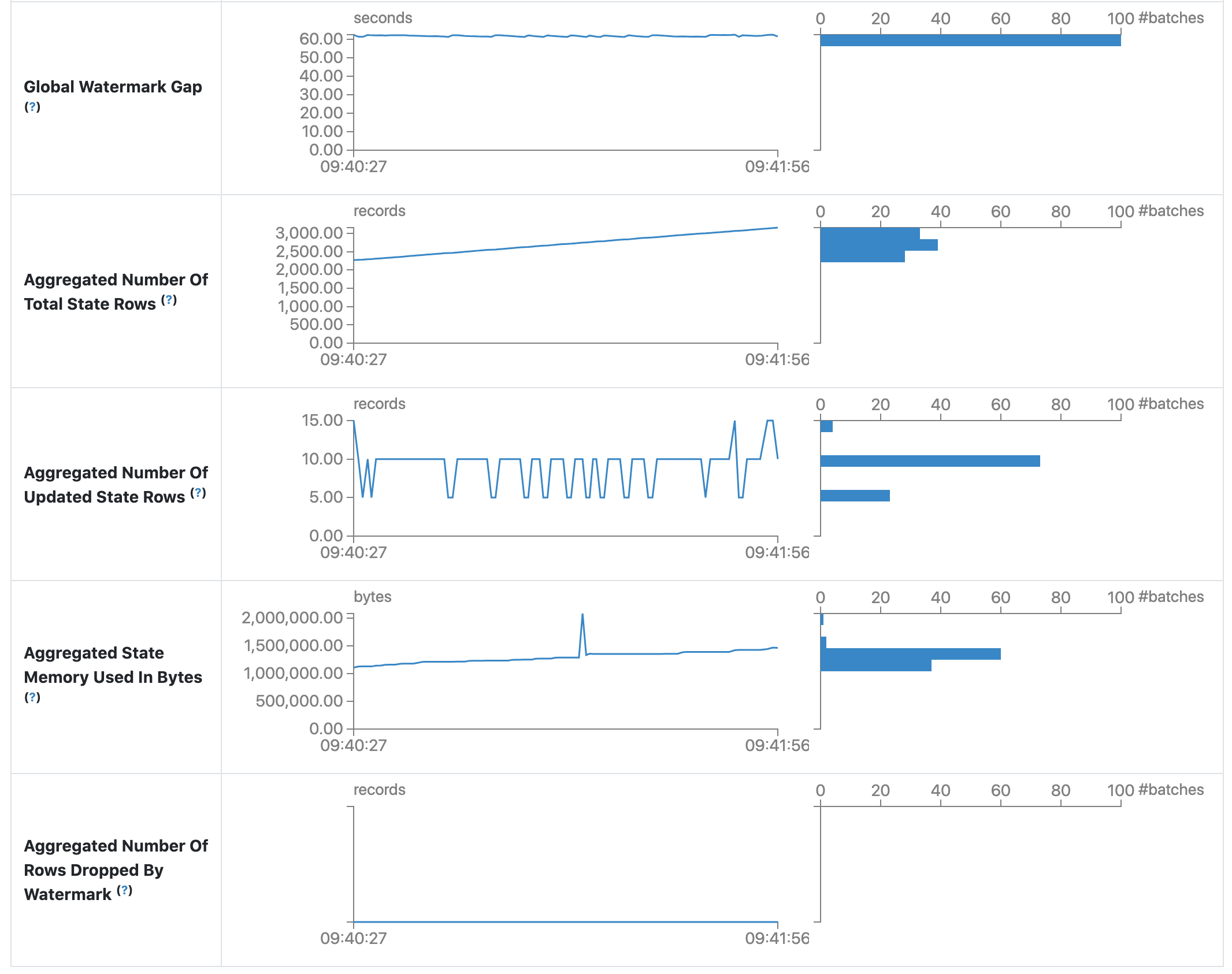
統計ページには、ストリーミングクエリの状態を把握するためのいくつかの有用なメトリクスが表示されます。現在、以下のメトリクスが含まれています。
- 入力レート。 (すべてのソースにわたる) 到着するデータの集計レート。
- 処理レート。 (すべてのソースにわたる) Spark がデータを処理する集計レート。
- 入力行数。 (すべてのソースにわたる) トリガーで処理されたレコードの集計数。
- バッチ期間。 各バッチの処理期間。
- 操作時間。 様々な操作を実行するのにかかった時間 (ミリ秒単位)。追跡される操作は次のとおりです。
- addBatch: マイクロバッチの入力データをソースから読み取り、処理し、バッチの出力をシンクに書き込むのにかかった時間。これは、マイクロバッチの時間の大部分を占めるはずです。
- getBatch: 現在のマイクロバッチの入力をソースから読み取るための論理クエリを準備するのにかかった時間。
- latestOffset & getOffset: このソースで利用可能な最大オフセットをクエリするのにかかった時間。
- queryPlanning: 実行プランを生成するのにかかった時間。
- walCommit: オフセットをメタデータログに書き込むのにかかった時間。
- グローバルウォーターマークギャップ。 バッチタイムスタンプとバッチのグローバルウォーターマークの間のギャップ。
- 総ステート行数の集計。 総ステート行数の集計。
- 更新ステート行数の集計。 更新されたステート行数の集計。
- 集計ステートメモリ使用量 (バイト単位)。 集計されたステートメモリの使用量 (バイト単位)。
- ウォーターマークによってドロップされたステート行数の集計。 ウォーターマークによってドロップされたステート行数の集計。
早期リリース版として、統計ページはまだ開発中であり、将来のリリースで改善される予定です。
ストリーミング (DStreams) タブ
アプリケーションが Spark Streaming と DStream API を使用している場合、Web UI にストリーミングタブが含まれます。このタブには、データストリーム内の各マイクロバッチのスケジューリング遅延と処理時間が表示され、ストリーミングアプリケーションのトラブルシューティングに役立ちます。
JDBC/ODBC サーバータブ
Spark が分散 SQL エンジンとして実行されている場合に、このタブを確認できます。セッションと送信された SQL 操作に関する情報が表示されます。
ページの最初のセクションには、JDBC/ODBC サーバーの一般情報 (起動時刻と稼働時間) が表示されます。

2 番目のセクションには、アクティブなセッションと完了したセッションに関する情報が含まれています。
- 接続のユーザーとIP。
- セッション情報にアクセスするためのセッション ID リンク。
- セッションの開始時刻、終了時刻、および期間。
- 総実行数は、このセッションで送信された操作の数です。

3 番目のセクションには、送信された操作の SQL 統計情報が含まれています。
- 操作を送信したユーザー。
- ジョブタブへのジョブ ID リンク。
- すべてのジョブをグループ化するクエリのグループ ID。アプリケーションはこのグループ ID を使用して、実行中のすべてのジョブをキャンセルできます。
- 操作の開始時刻。
- 結果を取得する前に、実行の終了時刻。
- 結果を取得した後、操作のクローズ時刻。
- 実行時間は、終了時刻と開始時刻の差です。
- 期間は、クローズ時刻と開始時刻の差です。
- ステートメントは、実行されている操作です。
- プロセスの状態。
- 開始、最初の状態、プロセスが開始されたとき。
- コンパイル済み、実行プランが生成された。
- 失敗、実行が失敗したか、エラーで終了したときの最終状態。
- キャンセル済み、実行がキャンセルされたときの最終状態。
- 完了、処理が完了し、結果の取得を待機中。
- クローズ済み、クライアントがステートメントをクローズしたときの最終状態。
- SQL ステートメントのエラー、または解析済み論理プラン、分析済み論理プラン、最適化済み論理プラン、および物理プランに関する実行プランの詳細。
