第4章:バグ退治 - PySparkのデバッグ#
PySparkは分散環境でアプリケーションを実行するため、これらのアプリケーションの監視とデバッグは困難です。どのノードが特定のコードを実行しているかを追跡するのは難しい場合があります。しかし、PySpark内にはデバッグを支援する複数の方法があります。このセクションでは、PySparkアプリケーションを効果的にデバッグする方法を概説します。
PySparkは、基盤となるエンジンとしてSparkを使用して動作し、Spark ConnectサーバーまたはPy4J(Spark Classic)を利用してSparkにジョブを送信し、計算します。
ドライバー側では、PySparkはSpark ConnectサーバーまたはPy4J(Spark Classic)を介してJVM上のSparkドライバーと対話します。`pyspark.sql.SparkSession`が作成および初期化されると、PySparkはSparkドライバーとの通信を開始します。
エグゼキュータ側では、PythonワーカーがPythonネイティブ関数またはデータの実行と管理を担当します。これらのワーカーは、Python UDFの実行など、PySparkアプリケーションがPythonとJVM間の対話を必要とする場合にのみ起動されます。これらは、pandas UDFまたはPySpark RDD APIを実行する場合などにオンデマンドで開始されます。
Spark UI#
Python UDFの実行#
PySparkでPython UDFをデバッグするには、printステートメントを追加するだけで済みますが、関数はエグゼキュータ上で実行されるため、クライアント/ドライバー側では出力が表示されません。Spark UIで表示できます。たとえば、動作するPython UDFがある場合
[1]:
from pyspark.sql.functions import udf
@udf("integer")
def my_udf(x):
# Do something with x
return x
以下に示すように、デバッグのためにprintステートメントを追加できます。
[2]:
@udf("integer")
def my_udf(x):
# Do something with x
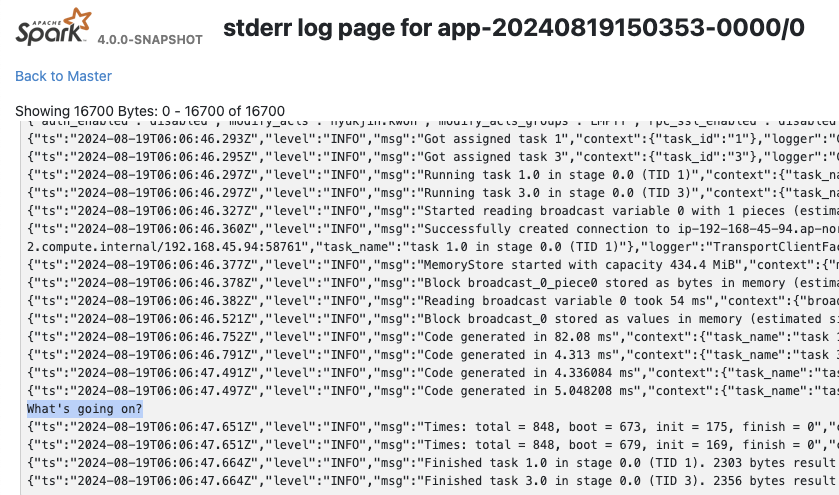
print("What's going on?")
return x
spark.range(1).select(my_udf("id")).collect()
[2]:
[Row(my_udf(id)=0)]
出力は、エグゼキュータタブの`stdout`/`stderr`の下のSpark UIで表示できます。
Python以外のUDF#
Python以外のUDFコードを実行する場合、デバッグは通常、Spark UIを介して、または`DataFrame.explain(True)`を使用して行われます。
たとえば、以下のコードは、大きなDataFrame(`df1`)と小さなDataFrame(`df2`)の間で結合を実行します。
[3]:
df1 = spark.createDataFrame([(x,) for x in range(100)])
df2 = spark.createDataFrame([(x,) for x in range(2)])
df1.join(df2, "_1").explain()
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- Project [_1#6L]
+- SortMergeJoin [_1#6L], [_1#8L], Inner
:- Sort [_1#6L ASC NULLS FIRST], false, 0
: +- Exchange hashpartitioning(_1#6L, 200), ENSURE_REQUIREMENTS, [plan_id=41]
: +- Filter isnotnull(_1#6L)
: +- Scan ExistingRDD[_1#6L]
+- Sort [_1#8L ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(_1#8L, 200), ENSURE_REQUIREMENTS, [plan_id=42]
+- Filter isnotnull(_1#8L)
+- Scan ExistingRDD[_1#8L]
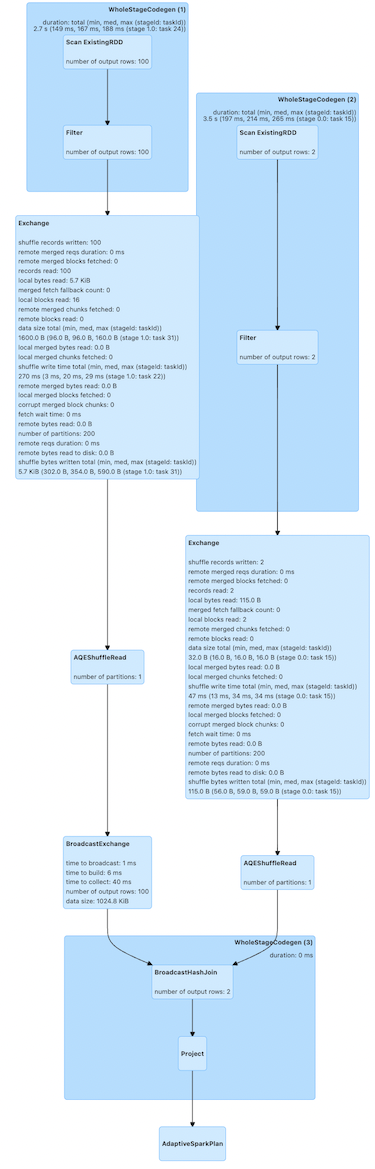
`DataFrame.explain`を使用すると、結合がどのように実行されるかを示す物理計画が表示されます。これらの物理計画は、全体の実行の個々のステップを表します。ここでは、データを交換(シャッフル)し、ソートマージ結合を実行します。
この方法で計画がどのように生成されるかを確認した後、ユーザーはクエリを最適化できます。たとえば、`df2`は非常に小さいので、エグゼキュータにブロードキャストしてシャッフルを削除できます。
[4]:
from pyspark.sql.functions import broadcast
df1.join(broadcast(df2), "_1").explain()
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- Project [_1#6L]
+- BroadcastHashJoin [_1#6L], [_1#8L], Inner, BuildRight, false
:- Filter isnotnull(_1#6L)
: +- Scan ExistingRDD[_1#6L]
+- BroadcastExchange HashedRelationBroadcastMode(List(input[0, bigint, false]),false), [plan_id=71]
+- Filter isnotnull(_1#8L)
+- Scan ExistingRDD[_1#8L]
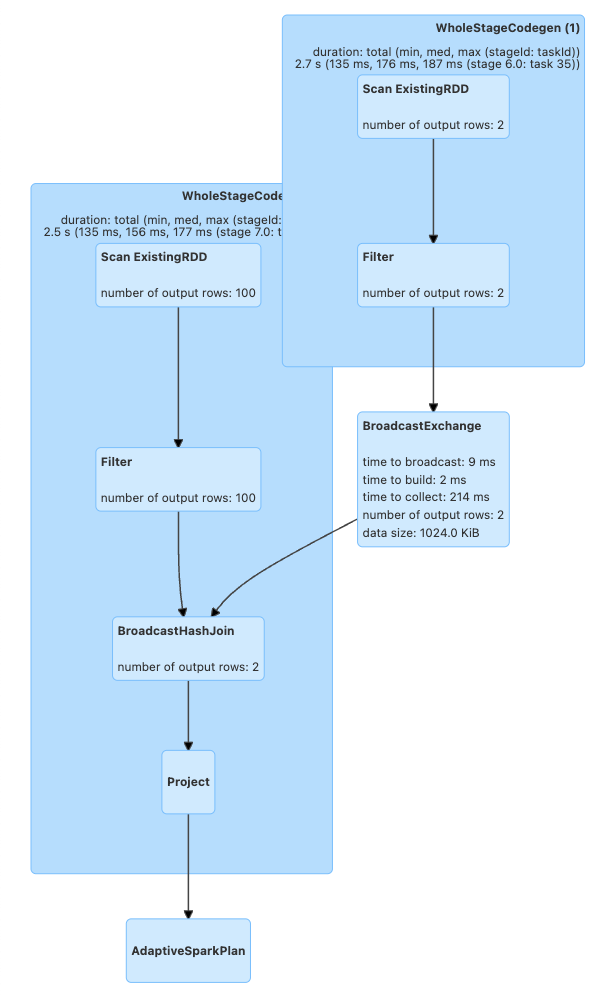
シャッフルが削除され、ブロードキャストハッシュ結合が実行されていることがわかります。
これらの最適化は、実行後にSpark UIのSQL / DataFrameタブでも視覚化できます。
[5]:
df1.join(df2, "_1").collect()
[5]:
[Row(_1=0), Row(_1=1)]
[6]:
df1.join(broadcast(df2), "_1").collect()
[6]:
[Row(_1=0), Row(_1=1)]
`top`と`ps`で監視#
ドライバー側では、PySparkシェルからプロセスIDを取得してリソースを監視できます。
[7]:
import os; os.getpid()
[7]:
23976
[8]:
%%bash
ps -fe 23976
UID PID PPID C STIME TTY TIME CMD
502 23976 21512 0 12:06PM ?? 0:02.30 /opt/miniconda3/envs/python3.11/bin/python -m ipykernel_launcher -f /Users/hyukjin.kwon/Library/Jupyter/runtime/kernel-c8eb73ef-2b21-418e-b770-92b946454606.json
エグゼキュータ側では、`grep`を使用してPythonワーカーのプロセスIDとリソースを見つけることができます。これらは`pyspark.daemon`からフォークされているためです。
[9]:
%%bash
ps -fe | grep pyspark.daemon | head -n 5
502 23989 23981 0 12:06PM ?? 0:00.59 python3 -m pyspark.daemon pyspark.worker
502 23990 23989 0 12:06PM ?? 0:00.19 python3 -m pyspark.daemon pyspark.worker
502 23991 23989 0 12:06PM ?? 0:00.19 python3 -m pyspark.daemon pyspark.worker
502 23992 23989 0 12:06PM ?? 0:00.19 python3 -m pyspark.daemon pyspark.worker
502 23993 23989 0 12:06PM ?? 0:00.19 python3 -m pyspark.daemon pyspark.worker
通常、ユーザーは`top`と特定されたPIDを利用して、PySparkのPythonプロセスのメモリ使用量を監視します。
PySparkプロファイラの使用#
メモリプロファイラ#
ドライバー側のデバッグのため、ユーザーは`memory_profiler`など、既存のほとんどのPythonツールを使用できます。これにより、行ごとにメモリ使用量を確認できます。ドライバープログラムが別のマシン(例:YARNクラスターモード)で実行されていない場合は、メモリプロファイラを使用してドライバー側のメモリ使用量をデバッグできます。たとえば、
[10]:
%%bash
echo "from pyspark.sql import SparkSession
#===Your function should be decorated with @profile===
from memory_profiler import profile
@profile
#=====================================================
def my_func():
session = SparkSession.builder.getOrCreate()
df = session.range(10000)
return df.collect()
if __name__ == '__main__':
my_func()" > profile_memory.py
python -m memory_profiler profile_memory.py 2> /dev/null
Filename: profile_memory.py
Line # Mem usage Increment Occurrences Line Contents
=============================================================
4 80.6 MiB 80.6 MiB 1 @profile
5 #=====================================================
6 def my_func():
7 79.0 MiB -1.7 MiB 1 session = SparkSession.builder.getOrCreate()
8 80.1 MiB 1.1 MiB 1 df = session.range(10000)
9 84.1 MiB 4.0 MiB 1 return df.collect()
どの行がどのくらいのメモリを消費するかを適切に示します。
PythonおよびPandas UDF#
注意:このセクションはSpark 4.0に適用されます。
PySparkは、Python/Pandas UDF用のリモート`memory_profiler`を提供します。これは、Jupyterノートブックなどの行番号付きのエディターで使用できます。SparkSessionベースのメモリプロファイラは、ランタイムSQL構成`spark.sql.pyspark.udf.profiler`を`memory`に設定することで有効にできます。
[11]:
from pyspark.sql.functions import pandas_udf
df = spark.range(10)
@pandas_udf("long")
def add1(x):
return x + 1
spark.conf.set("spark.sql.pyspark.udf.profiler", "memory")
added = df.select(add1("id"))
spark.profile.clear()
added.collect()
spark.profile.show(type="memory")
============================================================
Profile of UDF<id=16>
============================================================
Filename: /var/folders/qm/mlwmy16n5xx66ldgzmptzlc40000gp/T/ipykernel_23976/885006762.py
Line # Mem usage Increment Occurrences Line Contents
=============================================================
5 1472.6 MiB 1472.6 MiB 10 @pandas_udf("long")
6 def add1(x):
7 1473.9 MiB 1.3 MiB 10 return x + 1
UDF IDはクエリプランで確認できます。たとえば、以下に示す`ArrowEvalPython`内の`add1(...)#16L`です。
[12]:
added.explain()
== Physical Plan ==
*(2) Project [pythonUDF0#19L AS add1(id)#17L]
+- ArrowEvalPython [add1(id#14L)#16L], [pythonUDF0#19L], 200
+- *(1) Range (0, 10, step=1, splits=16)
パフォーマンスプロファイラ#
注意:このセクションはSpark 4.0に適用されます。
`Python Profilers`は、Python自体に組み込まれた便利な機能です。ドライバー側でこれを使用するには、ドライバー側のPySparkは通常のPythonプロセスであるため、通常のPythonプログラムと同様に使用できます。ただし、ドライバープログラムが別のマシン(例:YARNクラスターモード)で実行されている場合は除きます。
[13]:
%%bash
echo "from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
spark.range(10).collect()" > app.py
python -m cProfile -s cumulative app.py 2> /dev/null | head -n 20
549275 function calls (536745 primitive calls) in 3.447 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
2 0.000 0.000 3.448 1.724 app.py:1(<module>)
792/1 0.005 0.000 3.447 3.447 {built-in method builtins.exec}
128 0.000 0.000 2.104 0.016 socket.py:692(readinto)
128 2.104 0.016 2.104 0.016 {method 'recv_into' of '_socket.socket' objects}
124 0.000 0.000 2.100 0.017 java_gateway.py:1015(send_command)
125 0.001 0.000 2.099 0.017 clientserver.py:499(send_command)
138 0.000 0.000 2.097 0.015 {method 'readline' of '_io.BufferedReader' objects}
55 0.000 0.000 1.622 0.029 java_gateway.py:1313(__call__)
95 0.001 0.000 1.360 0.014 __init__.py:1(<module>)
1 0.000 0.000 1.359 1.359 session.py:438(getOrCreate)
1 0.000 0.000 1.311 1.311 context.py:491(getOrCreate)
1 0.000 0.000 1.311 1.311 context.py:169(__init__)
1 0.000 0.000 0.861 0.861 context.py:424(_ensure_initialized)
1 0.001 0.001 0.861 0.861 java_gateway.py:39(launch_gateway)
8 0.840 0.105 0.840 0.105 {built-in method time.sleep}
Python/Pandas UDF#
注意:このセクションはSpark 4.0に適用されます。
PySparkは、Python/Pandas UDF用のリモートPythonプロファイラを提供します。イテレータを入力/出力とするUDFはサポートされていません。SparkSessionベースのパフォーマンスプロファイラは、ランタイムSQL構成`spark.sql.pyspark.udf.profiler`を`perf`に設定することで有効にできます。例を以下に示します。
[14]:
import io
from contextlib import redirect_stdout
from pyspark.sql.functions import pandas_udf
df = spark.range(10)
@pandas_udf("long")
def add1(x):
return x + 1
added = df.select(add1("id"))
spark.conf.set("spark.sql.pyspark.udf.profiler", "perf")
spark.profile.clear()
added.collect()
# Only show top 10 lines
output = io.StringIO()
with redirect_stdout(output):
spark.profile.show(type="perf")
print("\n".join(output.getvalue().split("\n")[0:20]))
============================================================
Profile of UDF<id=22>
============================================================
2130 function calls (2080 primitive calls) in 0.003 seconds
Ordered by: internal time, cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
10 0.001 0.000 0.003 0.000 common.py:62(new_method)
10 0.000 0.000 0.000 0.000 {built-in method _operator.add}
10 0.000 0.000 0.002 0.000 base.py:1371(_arith_method)
10 0.000 0.000 0.001 0.000 series.py:389(__init__)
20 0.000 0.000 0.000 0.000 _ufunc_config.py:33(seterr)
10 0.000 0.000 0.001 0.000 series.py:6201(_construct_result)
10 0.000 0.000 0.000 0.000 cast.py:1605(maybe_cast_to_integer_array)
10 0.000 0.000 0.000 0.000 construction.py:517(sanitize_array)
10 0.000 0.000 0.002 0.000 series.py:6133(_arith_method)
10 0.000 0.000 0.000 0.000 managers.py:1863(from_array)
10 0.000 0.000 0.000 0.000 array_ops.py:240(arithmetic_op)
510 0.000 0.000 0.000 0.000 {built-in method builtins.isinstance}
UDF IDはクエリプランで確認できます。たとえば、以下の`ArrowEvalPython`内の`add1(...)#22L`です。
[15]:
added.explain()
== Physical Plan ==
*(2) Project [pythonUDF0#25L AS add1(id)#23L]
+- ArrowEvalPython [add1(id#20L)#22L], [pythonUDF0#25L], 200
+- *(1) Range (0, 10, step=1, splits=16)
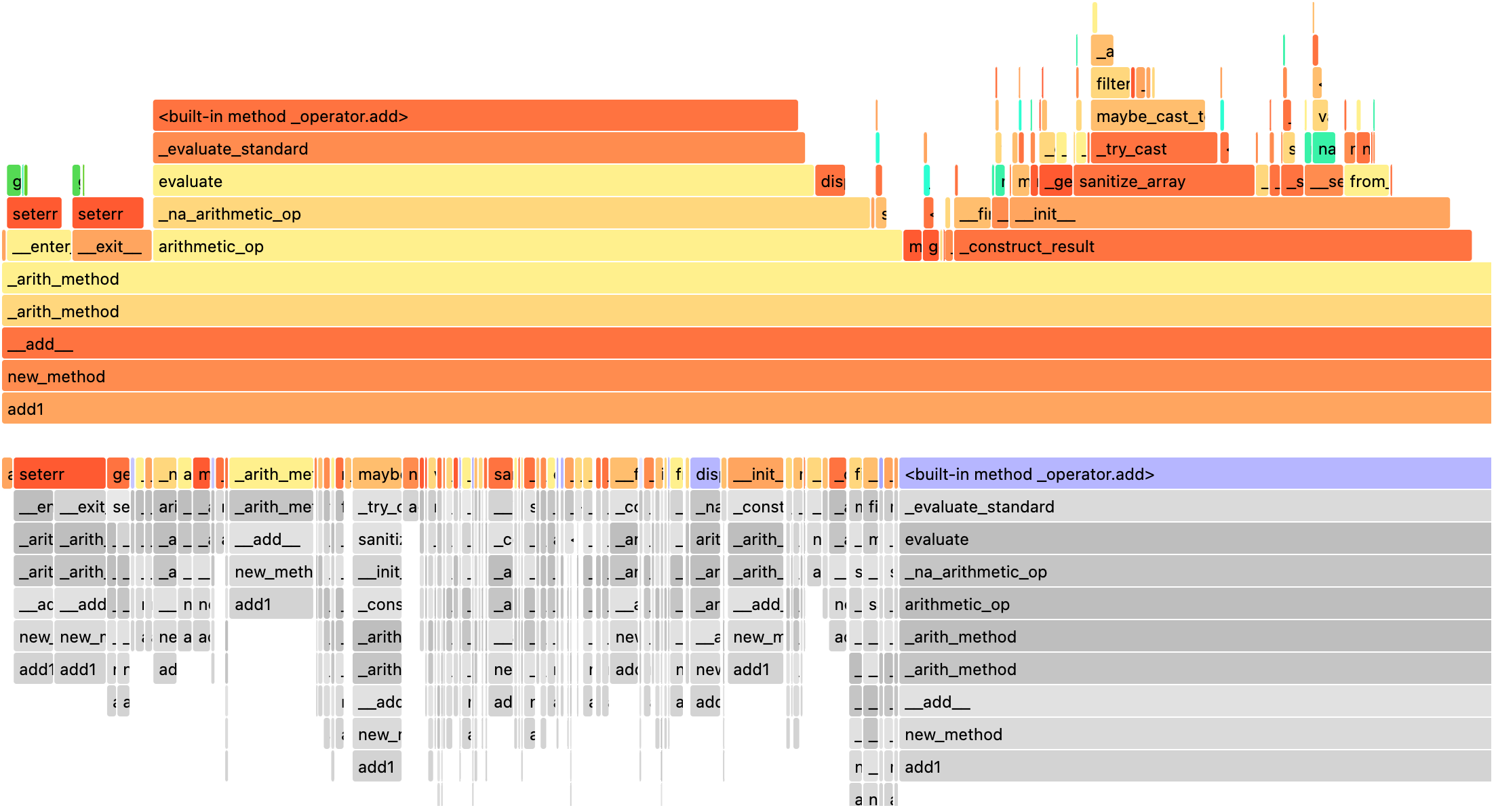
以下に示すように、事前に登録されたレンダラーで結果を表示できます。
[16]:
spark.profile.render(id=2, type="perf") # renderer="flameprof" by default
スタックトレースの表示#
注意:このセクションはSpark 4.0に適用されます。
デフォルトでは、JVMスタックトレースとPython内部トレースバックは非表示になっています。特にPython UDFの実行ではそうです。たとえば、
[17]:
from pyspark.sql.functions import udf
spark.range(1).select(udf(lambda x: x / 0)("id")).collect()
PythonException:
An exception was thrown from the Python worker. Please see the stack trace below.
Traceback (most recent call last):
File "/var/folders/qm/mlwmy16n5xx66ldgzmptzlc40000gp/T/ipykernel_23976/3806637820.py", line 3, in <lambda>
ZeroDivisionError: division by zero
完全な内部スタックトレースを表示するには、ユーザーはそれぞれ`spark.sql.execution.pyspark.udf.simplifiedTraceback.enabled`と`spark.sql.pyspark.jvmStacktrace.enabled`を有効にすることができます。
[18]:
spark.conf.set("spark.sql.execution.pyspark.udf.simplifiedTraceback.enabled", False)
spark.conf.set("spark.sql.pyspark.jvmStacktrace.enabled", False)
spark.range(1).select(udf(lambda x: x / 0)("id")).collect()
PythonException:
An exception was thrown from the Python worker. Please see the stack trace below.
Traceback (most recent call last):
File "/.../python/lib/pyspark.zip/pyspark/worker.py", line 1898, in main
process()
File "/.../python/lib/pyspark.zip/pyspark/worker.py", line 1890, in process
serializer.dump_stream(out_iter, outfile)
File "/.../python/lib/pyspark.zip/pyspark/serializers.py", line 224, in dump_stream
self.serializer.dump_stream(self._batched(iterator), stream)
File "/.../python/lib/pyspark.zip/pyspark/serializers.py", line 145, in dump_stream
for obj in iterator:
File "/.../python/lib/pyspark.zip/pyspark/serializers.py", line 213, in _batched
for item in iterator:
File "/.../python/lib/pyspark.zip/pyspark/worker.py", line 1798, in mapper
result = tuple(f(*[a[o] for o in arg_offsets]) for arg_offsets, f in udfs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/.../python/lib/pyspark.zip/pyspark/worker.py", line 1798, in <genexpr>
result = tuple(f(*[a[o] for o in arg_offsets]) for arg_offsets, f in udfs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/.../python/lib/pyspark.zip/pyspark/worker.py", line 114, in <lambda>
return args_kwargs_offsets, lambda *a: func(*a)
^^^^^^^^
File "/.../python/lib/pyspark.zip/pyspark/util.py", line 145, in wrapper
return f(*args, **kwargs)
^^^^^^^^^^^^^^^^^^
File "/.../python/lib/pyspark.zip/pyspark/worker.py", line 739, in profiling_func
ret = f(*args, **kwargs)
^^^^^^^^^^^^^^^^^^
File "/var/folders/qm/mlwmy16n5xx66ldgzmptzlc40000gp/T/ipykernel_23976/3570641234.py", line 3, in <lambda>
ZeroDivisionError: division by zero
[19]:
spark.conf.set("spark.sql.execution.pyspark.udf.simplifiedTraceback.enabled", True)
spark.conf.set("spark.sql.pyspark.jvmStacktrace.enabled", True)
spark.range(1).select(udf(lambda x: x / 0)("id")).collect()
PythonException:
An exception was thrown from the Python worker. Please see the stack trace below.
Traceback (most recent call last):
File "/var/folders/qm/mlwmy16n5xx66ldgzmptzlc40000gp/T/ipykernel_23976/3514597595.py", line 3, in <lambda>
ZeroDivisionError: division by zero
JVM stacktrace:
org.apache.spark.SparkException: Job aborted due to stage failure: Task 15 in stage 13.0 failed 1 times, most recent failure: Lost task 15.0 in stage 13.0 (TID 161) (ip-192-168-45-94.ap-northeast-2.compute.internal executor driver): org.apache.spark.api.python.PythonException: Traceback (most recent call last):
File "/var/folders/qm/mlwmy16n5xx66ldgzmptzlc40000gp/T/ipykernel_23976/3514597595.py", line 3, in <lambda>
ZeroDivisionError: division by zero
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator.handlePythonException(PythonRunner.scala:531)
at org.apache.spark.sql.execution.python.BasePythonUDFRunner$$anon$2.read(PythonUDFRunner.scala:103)
at org.apache.spark.sql.execution.python.BasePythonUDFRunner$$anon$2.read(PythonUDFRunner.scala:86)
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator.hasNext(PythonRunner.scala:485)
...
詳細については、スタックトレースを参照してください。
IDEデバッグ#
ドライバー側では、PySparkアプリケーションのデバッグにIDEを使用するために追加の手順は必要ありません。以下のガイドを参照してください。
エグゼキュータ側では、リモートデバッガを設定するにはいくつかの手順が必要です。以下のガイドを参照してください。