関数を変換して適用#
pandas-on-Spark DataFrame に関数を適用できる API は多数あります。DataFrame.transform()、DataFrame.apply()、DataFrame.pandas_on_spark.transform_batch()、DataFrame.pandas_on_spark.apply_batch()、Series.pandas_on_spark.transform_batch() などです。それぞれに異なる目的があり、内部で動作が異なります。このセクションでは、ユーザーがよく混乱するこれらの違いについて説明します。
transform と apply#
DataFrame.transform() と DataFrame.apply() の主な違いは、前者は入力と同じ長さの値を返す必要があるのに対し、後者はその必要がないことです。以下の例を参照してください。
>>> psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
>>> def pandas_plus(pser):
... return pser + 1 # should always return the same length as input.
...
>>> psdf.transform(pandas_plus)
>>> psdf = ps.DataFrame({'a': [1,2,3], 'b':[5,6,7]})
>>> def pandas_plus(pser):
... return pser[pser % 2 == 1] # allows an arbitrary length
...
>>> psdf.apply(pandas_plus)
この場合、各関数は pandas Series を受け取り、pandas API on Spark は以下のように分散処理で関数を計算します。
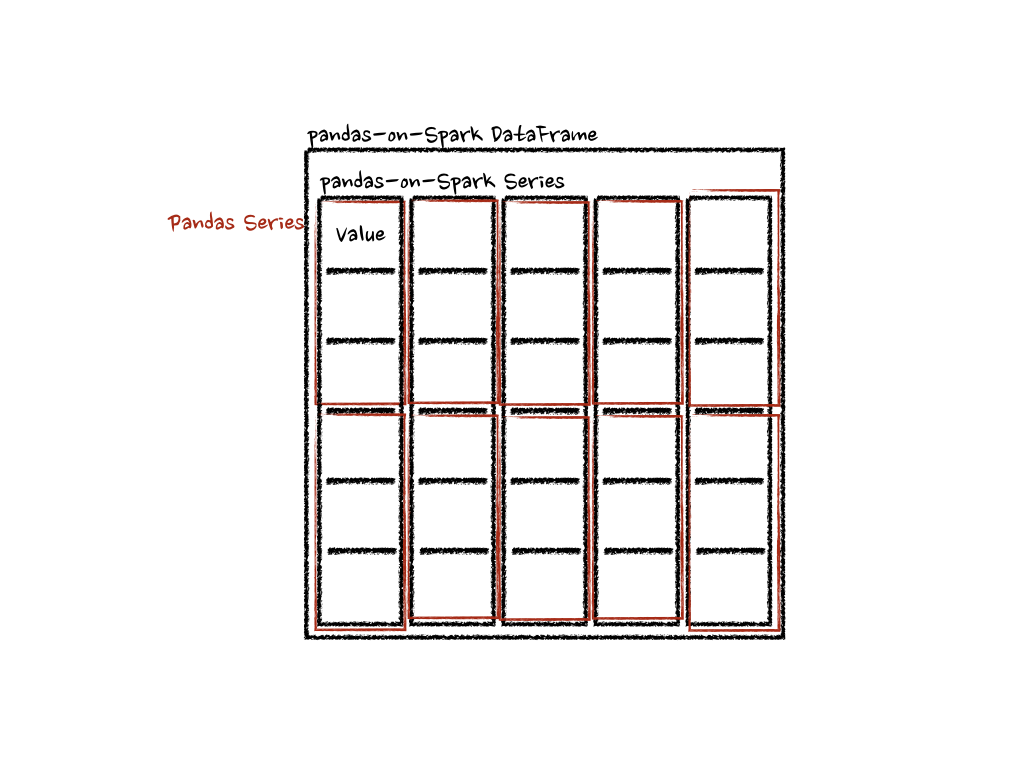
「列」軸の場合、関数は各行を pandas Series として受け取ります。
>>> psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
>>> def pandas_plus(pser):
... return sum(pser) # allows an arbitrary length
...
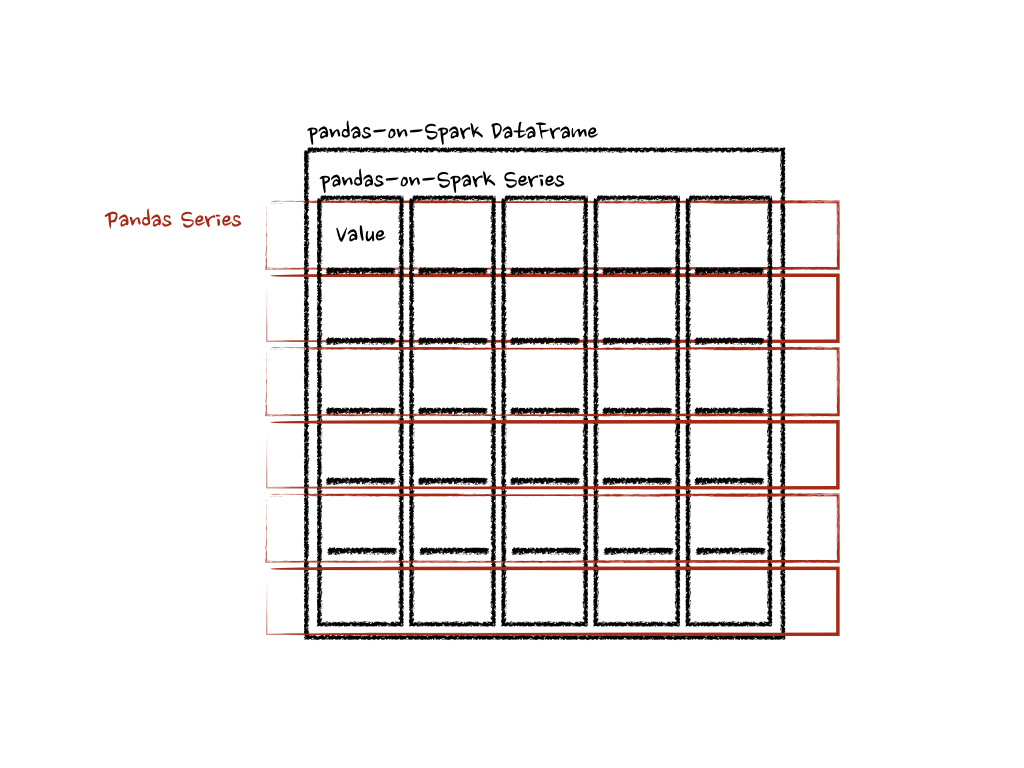
>>> psdf.apply(pandas_plus, axis='columns')
上記の例では、各行の合計を pandas Series として計算しています。以下を参照してください。
上記の例では、簡潔にするために型ヒントを使用していませんが、パフォーマンスの低下を避けるために使用することが推奨されます。API ドキュメントを参照してください。
pandas_on_spark.transform_batch と pandas_on_spark.apply_batch#
DataFrame.pandas_on_spark.transform_batch()、DataFrame.pandas_on_spark.apply_batch()、Series.pandas_on_spark.transform_batch() などでは、batch という接尾辞は、pandas-on-Spark DataFrame または Series の各チャンクを意味します。API は pandas-on-Spark DataFrame または Series をスライスし、入力と出力として pandas DataFrame または Series を使用して指定された関数を適用します。以下の例を参照してください。
>>> psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
>>> def pandas_plus(pdf):
... return pdf + 1 # should always return the same length as input.
...
>>> psdf.pandas_on_spark.transform_batch(pandas_plus)
>>> psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
>>> def pandas_plus(pdf):
... return pdf[pdf.a > 1] # allow arbitrary length
...
>>> psdf.pandas_on_spark.apply_batch(pandas_plus)
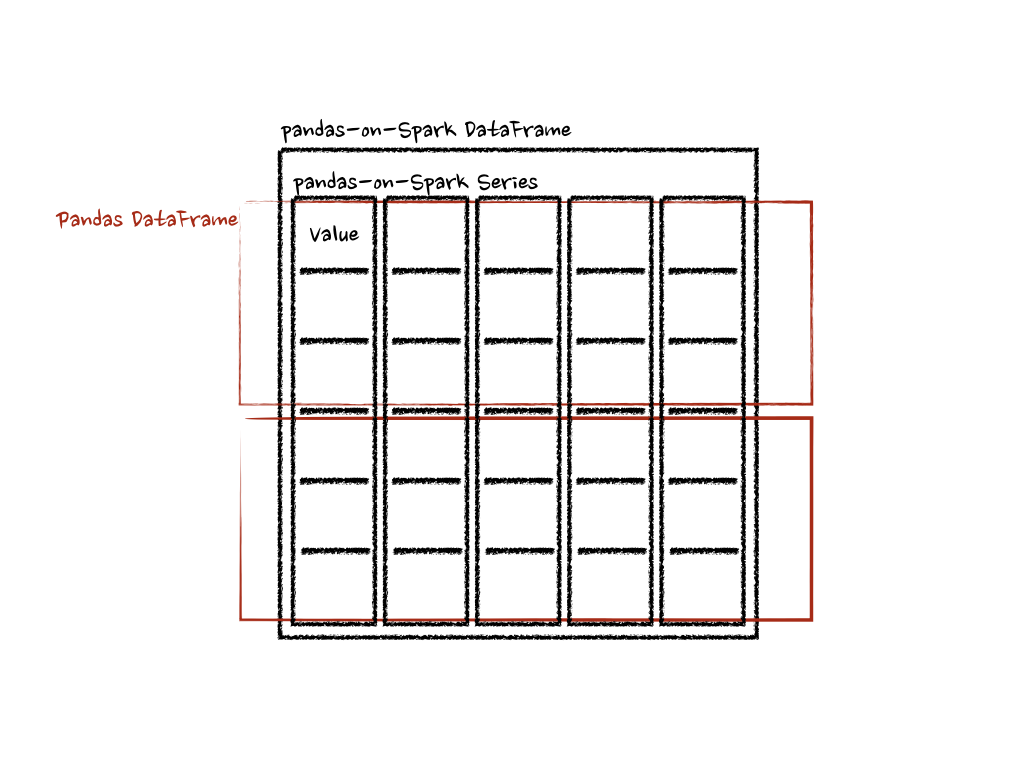
両方の例の関数は、pandas-on-Spark DataFrame のチャンクとして pandas DataFrame を受け取り、pandas DataFrame を出力します。Pandas API on Spark は、これらの pandas DataFrame を結合して pandas-on-Spark DataFrame を作成します。
DataFrame.pandas_on_spark.transform_batch() には長さの制約があり、入力と出力の長さは同じでなければなりませんが、DataFrame.pandas_on_spark.apply_batch() にはその制約はありません。しかし、DataFrame.pandas_on_spark.transform_batch() が Series を返す場合、その出力は同じ DataFrame に属するものとして扱われ、異なる DataFrame 間の操作によるシャッフルを回避できることに注意することが重要です。DataFrame.pandas_on_spark.apply_batch() の場合、その出力は常に新しい異なる DataFrame に属するものとして扱われます。詳細については、「異なる DataFrame に対する操作」も参照してください。
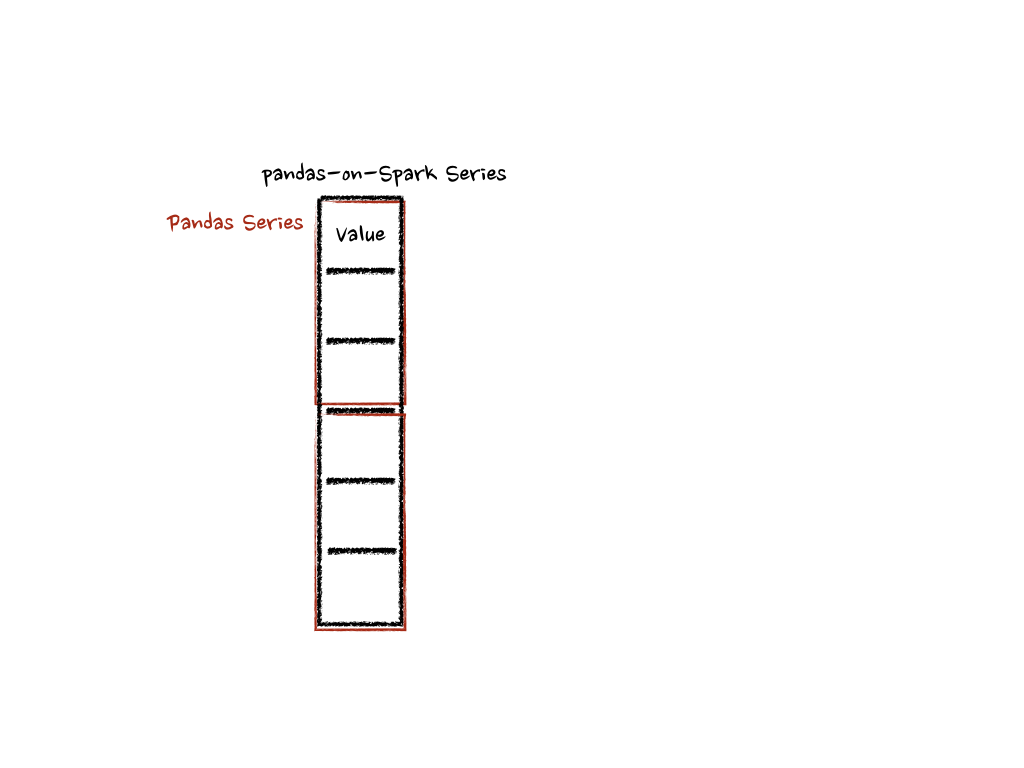
Series.pandas_on_spark.transform_batch() の場合も、DataFrame.pandas_on_spark.transform_batch() と同様ですが、pandas-on-Spark Series のチャンクとして pandas Series を受け取ります。
>>> psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
>>> def pandas_plus(pser):
... return pser + 1 # should always return the same length as input.
...
>>> psdf.a.pandas_on_spark.transform_batch(pandas_plus)
内部的には、pandas-on-Spark Series の各バッチは複数の pandas Series に分割され、各関数は以下のようにそれに対して計算を行います。
型推論やパフォーマンスの低下を防ぐための詳細など、さらに詳しい情報があります。API ドキュメントを参照してください。