PySpark のデバッグ#
PySpark は Spark をエンジンとして使用します。PySpark は Py4J を使用して Spark を活用し、ジョブの送信と計算を行います。
ドライバー側では、PySpark は Py4J を使用して JVM 上のドライバーと通信します。 pyspark.sql.SparkSession または pyspark.SparkContext が作成および初期化されると、PySpark は通信用の JVM を起動します。
エグゼキュータ側では、Python ワーカーが Python ネイティブ関数またはデータを実行および処理します。PySpark アプリケーションが Python ワーカーと JVM との対話を必要としない場合、これらは起動されません。Python ネイティブ関数またはデータを処理する必要がある場合、例えば pandas UDF または PySpark RDD API を実行する場合にのみ、遅延的に起動されます。
このページでは、JVM を使用したデバッグに焦点を当てるのではなく、ドライバーとエグゼキュータの両方の PySpark の Python 側のデバッグに焦点を当てます。JVM のプロファイリングとデバッグについては、便利な開発者ツール で説明されています。
注意:
ローカルで実行している場合、リモートデバッグ機能を使用せずに、IDE を使用してドライバー側を直接デバッグできます。IDE による PySpark の設定については、こちら で説明されています。
PySpark アプリケーションをデバッグするための他の多くの方法があります。たとえば、ここで説明されている PyCharm Professional を使用する代わりに、オープンソースの リモートデバッガー を使用してリモートデバッグできます。
リモートデバッグ (PyCharm Professional)#
このセクションでは、デモンストレーションを容易にするために、単一マシン上のドライバー側とエグゼキュータ側の両方でリモートデバッグについて説明します。エグゼキュータ側で PySpark をデバッグする方法は、ドライバー側で行う方法とは異なります。したがって、それぞれ個別にデモンストレーションします。他のマシンで PySpark アプリケーションをデバッグするには、PyCharm に固有の完全な指示を参照してください。これは こちら で説明されています。
まず、実行 メニューから 設定の編集… を選択します。これにより、実行/デバッグ構成ダイアログ が開きます。ツールバーの + 構成をクリックし、利用可能な構成のリストから Python デバッグサーバー を選択する必要があります。この新しい構成の名前 (例: MyRemoteDebugger) を入力し、ポート番号 (例: 12345) も指定します。
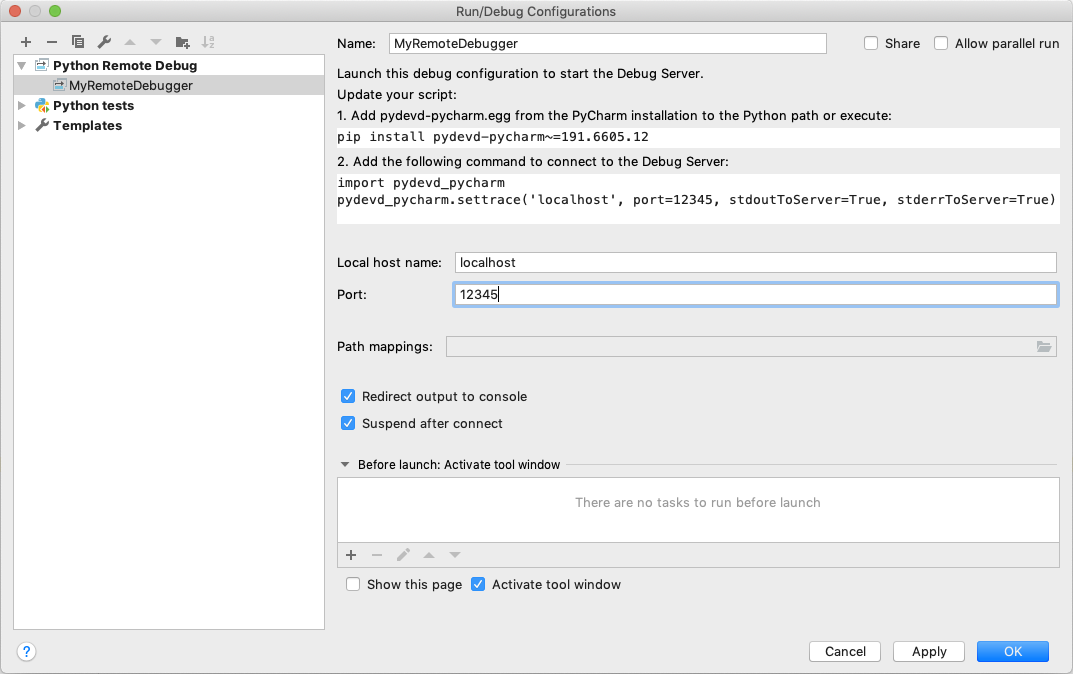
pydevd-pycharm パッケージをインストールする必要があります。前のダイアログにインストールコマンドが表示されます。pip install pydevd-pycharm~=<version of PyCharm on the local machine>
ドライバー側#
ドライバー側でデバッグするには、アプリケーションがデバッグサーバーに接続できる必要があります。 pydevd_pycharm.settrace を含むコードを PySpark スクリプトの先頭にコピーして貼り付けます。スクリプト名を app.py と仮定します。
echo "#======================Copy and paste from the previous dialog===========================
import pydevd_pycharm
pydevd_pycharm.settrace('localhost', port=12345, stdoutToServer=True, stderrToServer=True)
#========================================================================================
# Your PySpark application codes:
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
spark.range(10).show()" > app.py
あなたの MyRemoteDebugger でデバッグを開始してください。

spark-submit app.py
エグゼキュータ側#
エグゼキュータ側でデバッグするには、以下のような Python ファイルを現在の作業ディレクトリに準備します。
echo "from pyspark import daemon, worker
def remote_debug_wrapped(*args, **kwargs):
#======================Copy and paste from the previous dialog===========================
import pydevd_pycharm
pydevd_pycharm.settrace('localhost', port=12345, stdoutToServer=True, stderrToServer=True)
#========================================================================================
worker.main(*args, **kwargs)
daemon.worker_main = remote_debug_wrapped
if __name__ == '__main__':
daemon.manager()" > remote_debug.py
このファイルは、以下の構成を使用して PySpark アプリケーションの Python ワーカーとして使用されます。以下の構成で pyspark シェルを実行してください。
pyspark --conf spark.python.daemon.module=remote_debug
これでリモートデバッグの準備が整いました。あなたの MyRemoteDebugger でデバッグを開始してください。
spark.range(10).repartition(1).rdd.map(lambda x: x).collect()
リソース使用率の確認 (top および ps)#
ドライバーとエグゼキュータ上の Python プロセスは、top や ps コマンドなどの一般的な方法で確認できます。
ドライバー側#
ドライバー側では、プロセス ID とリソースを知るために、PySpark シェルから以下のように簡単にプロセス ID を取得できます。
>>> import os; os.getpid()
18482
ps -fe 18482
UID PID PPID C STIME TTY TIME CMD
000 18482 12345 0 0:00PM ttys001 0:00.00 /.../python
エグゼキュータ側#
エグゼキュータ側で確認するには、Python ワーカーは pyspark.daemon からフォークされるため、grep を使用してプロセス ID と関連リソースを特定するだけです。
ps -fe | grep pyspark.daemon
000 12345 1 0 0:00PM ttys000 0:00.00 /.../python -m pyspark.daemon
000 12345 1 0 0:00PM ttys000 0:00.00 /.../python -m pyspark.daemon
000 12345 1 0 0:00PM ttys000 0:00.00 /.../python -m pyspark.daemon
000 12345 1 0 0:00PM ttys000 0:00.00 /.../python -m pyspark.daemon
...
メモリ使用量のプロファイリング (Memory Profiler)#
memory_profiler は、メモリ使用量を1行ごとに確認できるプロファイラーの1つです。
ドライバー側#
ドライバープログラムを別のマシン (例: YARN クラスターモード) で実行していない限り、この便利なツールを使用してドライバー側のメモリ使用量を簡単にデバッグできます。PySpark スクリプト名を profile_memory.py と仮定します。以下のようにプロファイルできます。
echo "from pyspark.sql import SparkSession
#===Your function should be decorated with @profile===
from memory_profiler import profile
@profile
#=====================================================
def my_func():
session = SparkSession.builder.getOrCreate()
df = session.range(10000)
return df.collect()
if __name__ == '__main__':
my_func()" > profile_memory.py
python -m memory_profiler profile_memory.py
Filename: profile_memory.py
Line # Mem usage Increment Line Contents
================================================
...
6 def my_func():
7 51.5 MiB 0.6 MiB session = SparkSession.builder.getOrCreate()
8 51.5 MiB 0.0 MiB df = session.range(10000)
9 54.4 MiB 2.8 MiB return df.collect()
Python/Pandas UDF#
PySpark は、Python/Pandas UDF 用のリモート memory_profiler を提供します。これは、Jupyter notebook のような行番号付きのエディターで使用できます。イテレータを入力/出力として使用する UDF はサポートされていません。
SparkSession ベースのメモリプロファイラーは、ランタイム SQL 設定 spark.sql.pyspark.udf.profiler を memory に設定することで有効になります。Jupyter notebook での例を以下に示します。
from pyspark.sql.functions import pandas_udf
df = spark.range(10)
@pandas_udf("long")
def add1(x):
return x + 1
spark.conf.set("spark.sql.pyspark.udf.profiler", "memory")
added = df.select(add1("id"))
added.show()
spark.profile.show(type="memory")
結果のプロファイルは以下のとおりです。
============================================================
Profile of UDF<id=2>
============================================================
Filename: ...
Line # Mem usage Increment Occurrences Line Contents
=============================================================
4 974.0 MiB 974.0 MiB 10 @pandas_udf("long")
5 def add1(x):
6 974.4 MiB 0.4 MiB 10 return x + 1
UDF ID はクエリプランで確認できます。たとえば、ArrowEvalPython の add1(...)#2L のようなものです。
added.explain()
== Physical Plan ==
*(2) Project [pythonUDF0#11L AS add1(id)#3L]
+- ArrowEvalPython [add1(id#0L)#2L], [pythonUDF0#11L], 200
+- *(1) Range (0, 10, step=1, splits=16)
結果は、任意のレンダラー関数を使用してレンダリングできます。以下に例を示します。
def do_render(codemap):
# Your custom rendering logic
...
spark.profile.render(id=2, type="memory", renderer=do_render)
結果のメモリプロファイルをクリアできます。以下に例を示します。
spark.profile.clear(id=2, type="memory")
ホットループの特定 (Python Profilers)#
Python Profilers は、Python 自体に組み込まれた便利な機能です。これらは、多くの有用な統計情報とともに、Python プログラムの決定的プロファイリングを提供します。このセクションでは、ドライバー側とエグゼキュータ側の両方で、コストの高いコードパスまたはホットなコードパスを特定するために、これらをどのように使用するかについて説明します。
ドライバー側#
ドライバー側でこれを使用するには、ドライバープログラムを別のマシン (例: YARN クラスターモード) で実行している場合を除き、通常の Python プログラムの場合と同様に使用できます。
echo "from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
spark.range(10).show()" > app.py
python -m cProfile app.py
...
129215 function calls (125446 primitive calls) in 5.926 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1198/405 0.001 0.000 0.083 0.000 <frozen importlib._bootstrap>:1009(_handle_fromlist)
561 0.001 0.000 0.001 0.000 <frozen importlib._bootstrap>:103(release)
276 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:143(__init__)
276 0.000 0.000 0.002 0.000 <frozen importlib._bootstrap>:147(__enter__)
...
Python/Pandas UDF#
PySpark は、Python/Pandas UDF 用のリモート Python Profilers を提供します。イテレータを入力/出力として使用する UDF はサポートされていません。
SparkSession ベースのパフォーマンスプロファイラーは、ランタイム SQL 設定 spark.sql.pyspark.udf.profiler を perf に設定することで有効になります。例を以下に示します。
>>> from pyspark.sql.functions import pandas_udf
>>> df = spark.range(10)
>>> @pandas_udf("long")
... def add1(x):
... return x + 1
...
>>> added = df.select(add1("id"))
>>> spark.conf.set("spark.sql.pyspark.udf.profiler", "perf")
>>> added.show()
+--------+
|add1(id)|
+--------+
...
+--------+
>>> spark.profile.show(type="perf")
============================================================
Profile of UDF<id=2>
============================================================
2300 function calls (2270 primitive calls) in 0.006 seconds
Ordered by: internal time, cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
10 0.001 0.000 0.005 0.001 series.py:5515(_arith_method)
10 0.001 0.000 0.001 0.000 _ufunc_config.py:425(__init__)
10 0.000 0.000 0.000 0.000 {built-in method _operator.add}
10 0.000 0.000 0.002 0.000 series.py:315(__init__)
...
UDF ID はクエリプランで確認できます。たとえば、以下の ArrowEvalPython の add1(...)#2L のようなものです。
>>> added.explain()
== Physical Plan ==
*(2) Project [pythonUDF0#11L AS add1(id)#3L]
+- ArrowEvalPython [add1(id#0L)#2L], [pythonUDF0#11L], 200
+- *(1) Range (0, 10, step=1, splits=16)
結果は、事前に登録されたレンダラーを使用してレンダリングできます。以下に例を示します。
>>> spark.profile.render(id=2, type="perf") # renderer="flameprof" by default
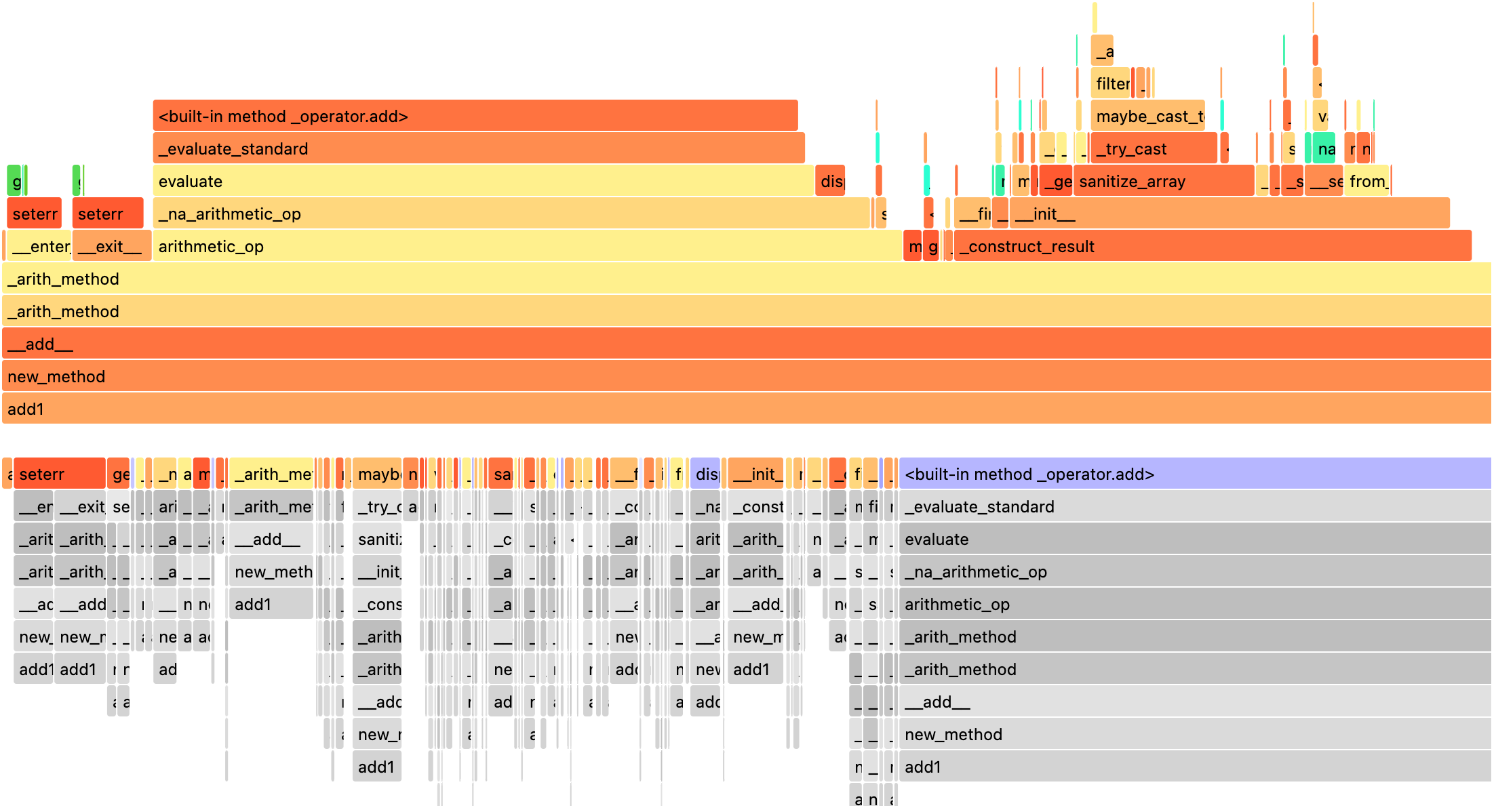
または、任意のレンダラー関数を使用してレンダリングできます。以下に例を示します。
>>> def do_render(stats):
... # Your custom rendering logic
... ...
...
>>> spark.profile.render(id=2, type="perf", renderer=do_render)
結果のパフォーマンスプロファイルをクリアできます。以下に例を示します。
>>> spark.profile.clear(id=2, type="perf")
一般的な例外/エラー#
PySpark SQL#
AnalysisException
AnalysisException は、SQL クエリプランの分析に失敗した場合に発生します。
例
>>> df = spark.range(1)
>>> df['bad_key']
Traceback (most recent call last):
...
pyspark.errors.exceptions.AnalysisException: Cannot resolve column name "bad_key" among (id)
解決策
>>> df['id']
Column<'id'>
ParseException
ParseException は、SQL コマンドの解析に失敗した場合に発生します。
例
>>> spark.sql("select * 1")
Traceback (most recent call last):
...
pyspark.errors.exceptions.ParseException:
[PARSE_SYNTAX_ERROR] Syntax error at or near '1': extra input '1'.(line 1, pos 9)
== SQL ==
select * 1
---------^^^
解決策
>>> spark.sql("select *")
DataFrame[]
IllegalArgumentException
IllegalArgumentException は、無効または不適切な引数を渡した場合に発生します。
例
>>> spark.range(1).sample(-1.0)
Traceback (most recent call last):
...
pyspark.errors.exceptions.IllegalArgumentException: requirement failed: Sampling fraction (-1.0) must be on interval [0, 1] without replacement
解決策
>>> spark.range(1).sample(1.0)
DataFrame[id: bigint]
PythonException
PythonException は、Python ワーカーからスローされます。
以下のように、Python ワーカーからスローされた例外の種類とそのスタックトレース (TypeError など) を確認できます。
例
>>> import pyspark.sql.functions as sf
>>> from pyspark.sql.functions import udf
>>> def f(x):
... return sf.abs(x)
...
>>> spark.range(-1, 1).withColumn("abs", udf(f)("id")).collect()
22/04/12 14:52:31 ERROR Executor: Exception in task 7.0 in stage 37.0 (TID 232)
org.apache.spark.api.python.PythonException: Traceback (most recent call last):
...
TypeError: Invalid argument, not a string or column: -1 of type <class 'int'>. For column literals, use 'lit', 'array', 'struct' or 'create_map' function.
解決策
>>> def f(x):
... return abs(x)
...
>>> spark.range(-1, 1).withColumn("abs", udf(f)("id")).collect()
[Row(id=-1, abs='1'), Row(id=0, abs='0')]
StreamingQueryException
StreamingQueryException は、StreamingQuery が失敗した場合に発生します。ほとんどの場合、Python ワーカーから PythonException としてラップされてスローされます。
例
>>> sdf = spark.readStream.format("text").load("python/test_support/sql/streaming")
>>> from pyspark.sql.functions import col, udf
>>> bad_udf = udf(lambda x: 1 / 0)
>>> (sdf.select(bad_udf(col("value"))).writeStream.format("memory").queryName("q1").start()).processAllAvailable()
Traceback (most recent call last):
...
org.apache.spark.api.python.PythonException: Traceback (most recent call last):
File "<stdin>", line 1, in <lambda>
ZeroDivisionError: division by zero
...
pyspark.errors.exceptions.StreamingQueryException: [STREAM_FAILED] Query [id = 74eb53a8-89bd-49b0-9313-14d29eed03aa, runId = 9f2d5cf6-a373-478d-b718-2c2b6d8a0f24] terminated with exception: Job aborted
解決策
StreamingQuery を修正して、ワークフローを再実行してください。
SparkUpgradeException
SparkUpgradeException は、Spark のアップグレードが原因でスローされます。
例
>>> from pyspark.sql.functions import to_date, unix_timestamp, from_unixtime
>>> df = spark.createDataFrame([("2014-31-12",)], ["date_str"])
>>> df2 = df.select("date_str", to_date(from_unixtime(unix_timestamp("date_str", "yyyy-dd-aa"))))
>>> df2.collect()
Traceback (most recent call last):
...
pyspark.sql.utils.SparkUpgradeException: You may get a different result due to the upgrading to Spark >= 3.0: Fail to recognize 'yyyy-dd-aa' pattern in the DateTimeFormatter. 1) You can set spark.sql.legacy.timeParserPolicy to LEGACY to restore the behavior before Spark 3.0. 2) You can form a valid datetime pattern with the guide from https://spark.dokyumento.jp/docs/latest/sql-ref-datetime-pattern.html
解決策
>>> spark.conf.set("spark.sql.legacy.timeParserPolicy", "LEGACY")
>>> df2 = df.select("date_str", to_date(from_unixtime(unix_timestamp("date_str", "yyyy-dd-aa"))))
>>> df2.collect()
[Row(date_str='2014-31-12', to_date(from_unixtime(unix_timestamp(date_str, yyyy-dd-aa), yyyy-MM-dd HH:mm:ss))=None)]
Spark 上の Pandas API#
Spark 上の Pandas API には、特定の一般的な例外/エラーがあります。
ValueError: シリーズまたはデータフレームを結合できません。異なるデータフレームから取得されたものです。
複数のシリーズまたはデータフレームを操作する際に、compute.ops_on_diff_frames が無効になっている場合 (デフォルトでは無効)、ValueError が発生します。このような操作は、基になる Spark フレームの結合によりコストが高くなる可能性があります。そのため、ユーザーはコストを認識し、必要に応じてのみフラグを有効にする必要があります。
Exception
>>> ps.Series([1, 2]) + ps.Series([3, 4])
Traceback (most recent call last):
...
ValueError: Cannot combine the series or dataframe because it comes from a different dataframe. In order to allow this operation, enable 'compute.ops_on_diff_frames' option.
解決策
>>> with ps.option_context('compute.ops_on_diff_frames', True):
... ps.Series([1, 2]) + ps.Series([3, 4])
...
0 4
1 6
dtype: int64
RuntimeError: pandas_udf からの結果ベクトルが期待される長さではありませんでした。
Exception
>>> def f(x) -> ps.Series[np.int32]:
... return x[:-1]
...
>>> ps.DataFrame({"x":[1, 2], "y":[3, 4]}).transform(f)
22/04/12 13:46:39 ERROR Executor: Exception in task 2.0 in stage 16.0 (TID 88)
org.apache.spark.api.python.PythonException: Traceback (most recent call last):
...
RuntimeError: Result vector from pandas_udf was not the required length: expected 1, got 0
解決策
>>> def f(x) -> ps.Series[np.int32]:
... return x
...
>>> ps.DataFrame({"x":[1, 2], "y":[3, 4]}).transform(f)
x y
0 1 3
1 2 4
Py4j#
Py4JJavaError
Py4JJavaError は、Java クライアントコードで例外が発生した場合に発生します。以下のように、Java 側でスローされた例外の種類とそのスタックトレース (java.lang.NullPointerException など) を確認できます。
例
>>> spark.sparkContext._jvm.java.lang.String(None)
Traceback (most recent call last):
...
py4j.protocol.Py4JJavaError: An error occurred while calling None.java.lang.String.
: java.lang.NullPointerException
..
解決策
>>> spark.sparkContext._jvm.java.lang.String("x")
'x'
Py4JError
Py4JError は、Python クライアントプログラムが Java 側で既に存在しないオブジェクトにアクセスしようとした場合など、その他のエラーが発生した場合に発生します。
例
>>> from pyspark.ml.linalg import Vectors
>>> from pyspark.ml.regression import LinearRegression
>>> df = spark.createDataFrame(
... [(1.0, 2.0, Vectors.dense(1.0)), (0.0, 2.0, Vectors.sparse(1, [], []))],
... ["label", "weight", "features"],
... )
>>> lr = LinearRegression(
... maxIter=1, regParam=0.0, solver="normal", weightCol="weight", fitIntercept=False
... )
>>> model = lr.fit(df)
>>> model
LinearRegressionModel: uid=LinearRegression_eb7bc1d4bf25, numFeatures=1
>>> model.__del__()
>>> model
Traceback (most recent call last):
...
py4j.protocol.Py4JError: An error occurred while calling o531.toString. Trace:
py4j.Py4JException: Target Object ID does not exist for this gateway :o531
...
解決策
Java 側にあるオブジェクトにアクセスします。
Py4JNetworkError
Py4JNetworkError は、ネットワーク転送中に問題が発生した場合 (例: 接続が失われた場合) に発生します。この場合、ネットワークをデバッグし、接続を再確立する必要があります。
スタックトレース#
スタックトレースを制御するための Spark 設定があります。
spark.sql.execution.pyspark.udf.simplifiedTraceback.enabledは、Python UDF およびデータソースからのトレースバックを簡略化するために、デフォルトで true になっています。spark.sql.pyspark.jvmStacktrace.enabledは、JVM スタックトレースを非表示にし、Python フレンドリーな例外のみを表示するために、デフォルトで false になっています。
上記の Spark 設定は、ログレベル設定とは独立しています。ログレベルは、pyspark.SparkContext.setLogLevel() を介して制御してください。